2 divisiones que se pueden formar con la igualdad 875 = 145 x 6 + 5
2 divisions that can be formed with equality 875 = 145 x 6 + 5
Answers
Two divisions that can be formed with the equality 875 = 145 x 6 + 5 are 175 = 29 x 6 + 1 and 125 = 20.71 x 6 + 0.71.
Divisions2 divisions that can be formed with the equality 875 = 145 x 6 + 5 are the following:
875 is divisible by 1, 5 and 7. So:
875 / 5 = 175145 / 5 = 2929 x 6 = 174175 = 29 x 6 + 1875 / 7 = 125145 / 7 = 20.7120.71 x 6 = 124.29 125 - 124.29 = 0.71125 = 20.71 x 6 + 0.71
Learn more about divisions in https://brainly.com/question/21416852
#SPJ1
Related Questions
The circles are identical. What is the circumference of each circle? Circle 1 radius =3x. Circle 2 radius = 2x+3
Answers
Answer:
19.44x and 12.96x+19.44
Step-by-step explanation:
Given data
Circle 1 radius =3x.
Circle 2 radius = 2x+3
The expression for the circumference is
C= 2πr
Circle 1 radius =3x.
C= 2*3.24*(3x)
C= 19.44x
Circle 1 radius = 2x+3
C= 2*3.24*(2x+3)
C=6.48*(2x+3)
C=12.96x+19.44
2. In a certain school, there are 7 teachers for every 252 students. If there are 468 students, how many
teachers are needed?
Answers
Answer:
66.6
Step-by-step explanation:
If 7 teachers for 252 student
We divide 468÷7= 66.6
66.6 teacher
Here you are
A post office has 2 clerks. Alice enters the post office while 2 other customers, Bob and Claire, are being served by the 2 clerks. She is next in line. Suppose a clerk’s serving time for any customer follows an exponential distribution with parameter λ independently. Customers will be served once any of the clerks are available.
What is the probability that Bob the last customer to leave the post office?
Answers
The probability that Bob is the last customer to leave the post office comes out as (1 - e^(-λx))^2. The probability that Bob is the last customer to leave the post office can be calculated using the exponential distribution formula.
The exponential distribution is a continuous probability distribution used to model the time between events in a Poisson process. The formula for the exponential distribution is: P(X=x) = λe^(-λx)
Where X is the random variable representing the time between events, λ is the rate parameter, and e is the base of the natural logarithm.
P(Bob is the last customer to leave) = P(Bob's serving time > Alice's serving time) * P(Bob's serving time > Claire's serving time). Since the serving times follow an exponential distribution with parameter λ, we can use the formula to calculate the probabilities:
P(Bob's serving time > Alice's serving time) = ∫_0^∞ λe^(-λx) dx = 1 - e^(-λx)
P(Bob's serving time > Claire's serving time) = ∫_0^∞ λe^(-λx) dx = 1 - e^(-λx)
P(Bob is the last customer to leave) = (1 - e^(-λx))^2
Therefore, the probability that Bob is the last customer to leave the post office is (1 - e^(-λx))^2.
Know more about exponential distribution here:
https://brainly.com/question/28235111
#SPJ11
EASY BRAINLIEST PLEASE HELP!!
-if you answer correctly ill give you brainliest which will give you 35pts-
(if you put links or don't answer accordingly im reporting your account)


Answers
Answer:
C. 175π/9 in²Step-by-step explanation:
m∠CBD = 2m∠CADm∠CBD = 2*35° = 70°Area of the sector B:
A = πr²*70/360 =
π*10²*7/36 =
175π/9 in²
Correct choice is C
Answer:
given;
inscribed angle =35°
central angle=35×2=70°
radius [r]=10in
area of shaded region=70°/360×πr²
=70°/360×π×10²=159π/9 or 61.08in²
here you can get free question answer things, so
1+0 = ?
u can get free “helped people”by this
Answers
Answer:
the answer is 1
........
1+0=1
Because anything plus zero equals itself (Example) :
3+0=3, 4+0=4, etc
Therefore
1+0=1
Have a good day!
the probability of the union of two events occurring can never be more than the probability of the intersection of two events occurring. true/false
Answers
The given statement "the probability of the union of two events occurring can never be more than the probability of the intersection of two events occurring." is False.
The union of two events A and B represents the event that at least one of the events A or B occurs. The probability of the union of two events can be calculated using the formula:
P(A or B) = P(A) + P(B) - P(A and B)
On the other hand, the intersection of two events A and B represents the event that both events A and B occur. The probability of the intersection of two events can be calculated using the formula:
P(A and B) = P(A) * P(B|A)
where P(B|A) is the conditional probability of B given that A has occurred.
It is possible for the probability of the union of two events to be greater than the probability of the intersection of two events if the two events are not mutually exclusive.
In this case, the probability of both events occurring together (the intersection) may be relatively small, while the probability of at least one of the events occurring (the union) may be relatively high.
In summary, the probability of the union of two events occurring can sometimes be greater than the probability of the intersection of two events occurring, depending on the relationship between the events.
To learn more about probability click on,
https://brainly.com/question/30648713
#SPJ4
At the Hawaii Pineapple Company, managers are interested in the size of the pineapples grown in the company's fields. Last year, the weight of the pineapples harvested from one large field was roughly normally distributed with a mean of 31 ounces and a standard deviation of 4 ounces. A different irrigation system was installed in this field after the growing season. Managers wonder if the the mean weight of pineapples grown in the field this year will be different from last.
Required:
a. Write out the null, and alternative hypotheses Hain terms of the population mean μ.
b. Explain Type 1 and Type 2 errors of the test in context e) What sample size should the managers use to ensure their test has power of at least 0.9 to detect a-33 (assuming Æ¡-4)?
Answers
a) The mean weight of pineapples grown in the field this year is different from the mean weight of pineapples grown last year. b) The power to detect an increase of 2 ounces in the mean weight of pineapples (μa = 33 ounces) is approximately 0.932, and the probability of making a Type 2 error with a true mean of 33 ounces is approximately 0.068.
(a) The null hypothesis (H0) and alternative hypothesis (Ha) can be written as follows:
Null Hypothesis (H0): The mean weight of pineapples grown in the field this year is equal to the mean weight of pineapples grown last year (μ = 31 ounces).
Alternative Hypothesis (Ha): The mean weight of pineapples grown in the field this year is different from the mean weight of pineapples grown last year (μ ≠ 31 ounces).
(b) To calculate the power and the probability of making a Type 2 error, we need to assume the population mean weight of pineapples this year (μa) is 33 ounces. We also need to determine the critical value for the given significance level (α) of 0.05.
Given that the sample size (n) is 30, the population standard deviation (σ) is 4 ounces, and the mean weight under the alternative hypothesis (μa) is 33 ounces, we can calculate the test statistic (z) using the formula:
z = (\(\bar x\) - μa) / (σ / √n)
where \(\bar x\) is the sample mean.
With \(\bar x\) = 31 ounces, σ = 4 ounces, μa = 33 ounces, and n = 30, we can calculate the test statistic:
z = (31 - 33) / (4 / √30)
z = -2 / (4 / √30)
z = -2 / (4 / 5.477)
z = -2 / 1.0954
z ≈ -1.825
Using a standard normal distribution table or calculator, we can find the corresponding p-value for this z-value. Let's assume it is approximately 0.034 (one-tailed test).
The power of the test can be calculated as 1 minus the probability of a Type 2 error. Since the alternative hypothesis is two-sided, we divide the significance level (α) by 2 and find the corresponding critical z-value. Let's assume it is approximately 1.96 (two-tailed test).
Now we can calculate the power using the formula:
Power = 1 - P(Type 2 Error) = 1 - P(z < -1.96 or z > 1.96)
P(Type 2 Error) = P(z < -1.96 or z > 1.96) ≈ 2 * P(z < -1.96) (assuming symmetry)
P(Type 2 Error) ≈ 2 * 0.034 ≈ 0.068
To know more about mean weight:
https://brainly.com/question/32750508
#SPJ4
a(n) ____ data type must be used in arithmetic operations. a. string b. numeric c. character d. either a or b
Answers
The type of data that must be used in the arithmetic operation is numeric. Thus, the required answer to the provided question is Option B
Arithmetic operation means the method to find basic calculations like addition, subtraction, multiplication, and division on the given command.
For instance = 5 + 3 = 8
the above-given example is a perfect form of arithmetic operation that focuses on the using ability of numeric data to initiate calculations without any errors in the process. Furthermore, there are no variables involved that can hamper the process of calculation.
therefore, we can safely say that arithmetic operations can't survive without the numeric data and it will be impossible to perform calculations.
To learn more about arithmetic operation,
https://brainly.com/question/4721701
#SPJ4
it is used to represent the product
Answers
15.6 times a number x
Answers
Answer: x × 15.6
The word "times" in the question indicates that we need to multiply a number x with 15.6.
Hope that helps...
Help please!!!!! I am confused. If any one can help I would be great full (1-39)
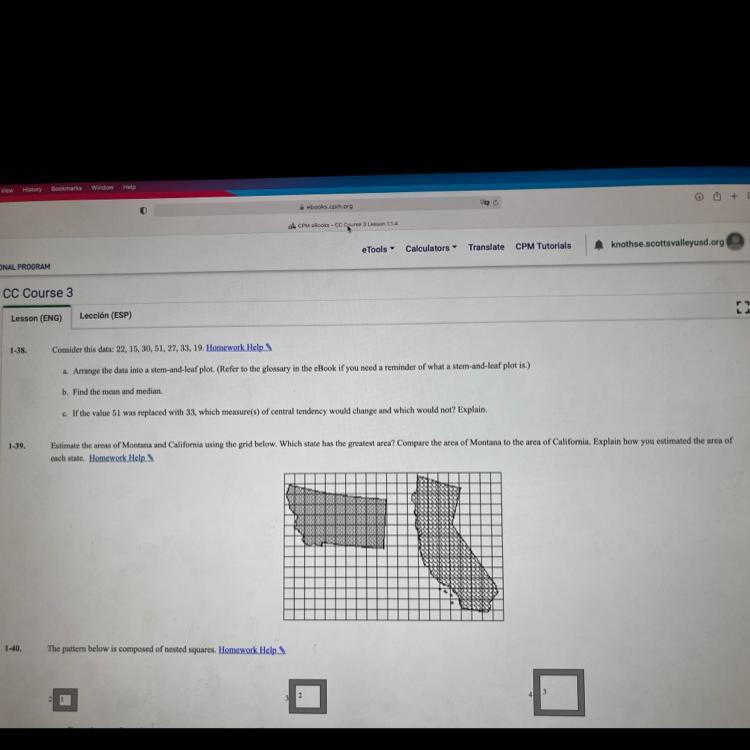
Answers
Answer:
montana
Step-by-step explanation:
I estimated montana by multiplying what was inside of a rectangle shape and then included the little outside parts
for california i did the same except used two rectangles
WHAT IS THIS. draw the line x=2 on the grid. please help
Answers
Answer The picture shows you where to place your line
Step-by-step explanation:

Answer This PPPPLLLLLZZZZ
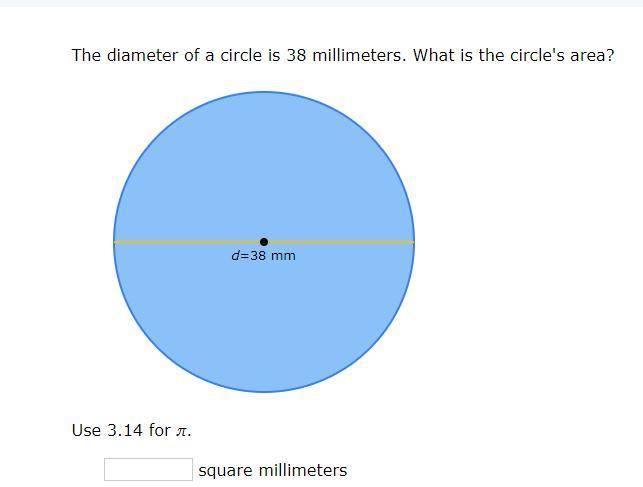
Answers
Answer:
1133.54 square millimetersStep-by-step explanation:
Area = πr^2
= 3.14 × (38/2)^2
= 3.14 × 361
= 1133.54 mm^2
Cost equation
Y=10x + 15
Y=25x + 8
At what point does these cost the same.
Answers
Answer:
x=7/15
Step-by-step explanation:
I'm not sure what x means but if you solve the equation it is 7/15
First you would set 10x+15 equal to 25x+8 which would look like 10x+15=25x+8
Then you would combine like terms by subtracting 8 from both sides to get 10x+7=25x
Then subtract 10x from both sides and get 7=15x
So then to get x by itself you would divide both sides by 15 and get 7/15=x
18 div 3 - 7 + 2 x 5
Me doing the answer:


Answers
Answer:
3
Step-by-step explanation:
calculate the lenght, in cm, the lenght of BD
help pleasee, its due in 10 mins

Answers
Answer:
4cm
Step-by-step explanation:
height² = hypotenuse²- base ²
h²= 5²-3²
= 25-9
=16
h= √16
h=4cm
can 5,7 and 13 make a triangle
Answers
Answer:
No
Step-by-step explanation:
5+7=12
12>13 X
13+5=18
18>13 YES
13+7=20
20>5 YES
If all equations were true, it would make a triangle, but since only 2 are true, it doesn't make a triangle.
---
hope it helps
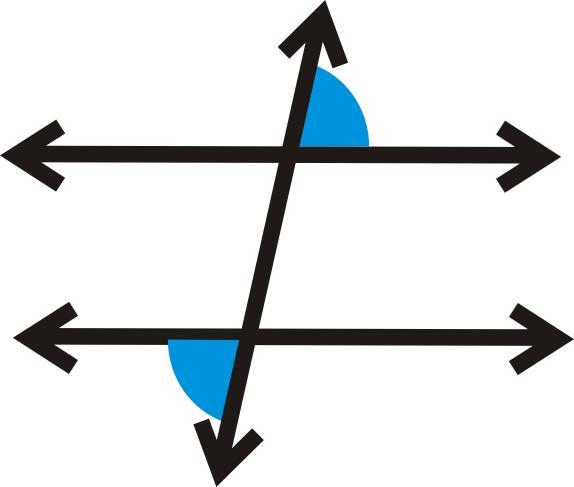
What angle are these?

Answers
Answer:
Corresponding Angles and Alternate Exterior
Step-by-step explanation:
The angles are corresponding if same side in a parallel.
This is because as the lines are parallel to one another that means that the next following angle measure is the same in approach.
For the other problems if they are opposite sides from one another.
They are called alternate exteriors.

HELP
im dont know this

Answers
Answer:
C
Step-by-step explanation:
use 0 and 3 for example:
replace x with 0 give you 2*0=0
add 0 with 3 and you get 3
x+8=6 you have to solve for x.
Answers
Answer:
x= -2
Step-by-step explanation:
8-2=6
also, 8-8=0, 6-8= -2
x=-2
Hope this helps:)- please crown me brainliest!
For a distribution that is skewed right the median is.
Answers
For a distribution that is skewed right, the median is typically less than the mean and is located to the left of the distribution's peak.
It represents the middle value when the data is arranged in ascending order and is less affected by extreme outliers compared to the mean. The median provides a measure of central tendency that is more representative of the "typical" value in a positively skewed distribution.
In a skewed right distribution, the tail of the distribution extends towards the higher values. This indicates that there are relatively more lower values and fewer higher values in the dataset. As a result, the mean is pulled towards the higher values, making it larger than the median.
The median, on the other hand, represents the middle value in the dataset when arranged in ascending order. It is less sensitive to extreme outliers compared to the mean because it focuses on the middle value rather than the overall distribution. Therefore, in a skewed right distribution, the median tends to be smaller than the mean and is located to the left of the peak of the distribution.
The use of median in a skewed right distribution helps provide a more robust measure of central tendency, as it is less influenced by extreme values and better represents the typical value in the data.
To learn more about ascending click here:
brainly.com/question/30325384
#SPJ11
The 3rd term of an arithmetic sequence is 1407 and the 10th term is 1183. Calculate the number of positive terms in the sequence.
Answers
Answer:
Let a be the first term and d be the common difference.
3rd term = 1407
a+2d = 1407 ------- 1
10th term = 1183
a+9d = 1183 ------- 2
By solving 1 and 2, a = 1471 and d = -32
so the general term T(n) = 1471 + (n-1)(-32)
= 1471 - 32n +32
= -32n + 1503
-32n + 1503 \(\geq\) 0
-32n \(\geq\) -1503
n \(\leq\) 46.96875
The number of positive terms = 46
Find the component form of the vector that translates A(-4,8) to A'(7,-9)
Answers
The component form of the vector that translates A to A' is (11, -17)
A translation is a type of transformation that takes each point in a figure and slides it the same distance in the same direction.
In translation, the shape of the figure does not change but its size may change.
Other transformation processes are reflection and rotation.
The component form of the vector is governed by the rule; A' - A
so we subtract corresponding x- coordinates and corresponding y- coordinates
A' - A = (7, -9) - (-4, 8)
= ( 7 - - 4, -9 - 8)
-= ( 11, -17)
In conclusion, the vector that translates A to A' is ( 11, -17 )
Learn more about translation: https://brainly.com/question/12861087
#SPJ1
HELP....I am very bad a math...will mark brain..

Answers
Answer:
Distributive property
Step-by-step explanation:
what is the angle of elevation to a building 1000 m away that is 300 m high?
Answers
Let h be height of building
then In ΔABC
AB/BC =tan60degree
h/100 = root 3
h= 100 root 3
PLEASE MARK BRAINLIST!!
The required angle of elevation of the building is 16.7°.
Given that,
what is the angle of elevation to a building 1000 m away that is 300 m high is to be determined.
These are the equation that contains trigonometric operators such as sin, cos.. etc.. In algebraic operations.
Here,
The angle of the elevation is given as,
TanФ = 300/1000
Ф = tan⁻¹(3/10)
Ф = 16.7°
Thus, the required angle of elevation of the building is 16.7°.
Learn more about trigonometry equations here:
brainly.com/question/22624805
#SPJ2
find the average value of f over the given rectangle. f(x, y) = 2ey x ey , r = [0, 14] ⨯ [0, 1]
Answers
The average value of f over the given rectangle is 572.52
The average value of a function f(x, y) over a rectangle R can be found by computing the double integral of f(x, y) over R and dividing by the area of R.
Let's first compute the integral of f(x, y) over R = [0, 14] ⨯ [0, 1]:
∬<sub>R</sub> f(x, y) dA = ∫<sub>0</sub><sup>1</sup> ∫<sub>0</sub><sup>14</sup> 2ey x ey dx dy
= ∫<sub>0</sub><sup>1</sup> [y(2e<sup>14y</sup> - 2)] dy
= [ye<sup>14y</sup> - y]<sub>0</sub><sup>1</sup> = e^14 - 1
The area of R is A = (14 - 0)(1 - 0) = 14, so the average value of f(x, y) over R is:
(1/A)∬<sub>R</sub> f(x, y) dA = (1/14)(e^14 - 1) ≈ 572.52
Therefore, the average value of f(x, y) over the rectangle R is approximately 572.52.
Learn more about average value at https://brainly.com/question/4834402
#SPJ11
the national center for education statistics reported that of college students work to pay for tuition and living expenses. assume that a sample of college students was used in the study. a. provide a confidence interval for the population proportion of college students who work to pay for tuition and living expenses. (to decimals) 0.42 , 0.52 b. provide a confidence interval for the population proportion of college students who work to pay for tuition and living expenses. (to decimals) 0.41 , 0.53 c. what happens to the margin of error as the confidence is increased from to ? the margin of error becomes larger
Answers
For part a, the confidence interval for the population proportion of college students who work to pay for tuition and living expenses is 0.42 to 0.52, with a certain level of confidence (usually 95% or 99%).
For part b, the confidence interval is slightly wider and ranges from 0.41 to 0.53. This could be due to a larger sample size or a lower level of confidence.
For part c, as the confidence level increases from 95% to 99%, the margin of error becomes larger.
a. To calculate the confidence interval for the population proportion of college students who work to pay for tuition and living expenses, we use the given range of 0.42 to 0.52. This interval indicates that we can be confident that the true population proportion falls between 42% and 52% of college students. This means that we are 95% confident that the true population proportion falls within this interval based on the sample data.
b. Similarly, for the second provided confidence interval, we use the given range of 0.41 to 0.53. This interval indicates that we can be confident that the true population proportion falls between 41% and 53% of college students.
c. When the confidence level is increased, the margin of error becomes larger. This is because a higher confidence level requires a wider interval to ensure that the true population proportion falls within the specified range with greater certainty. This is because a higher level of confidence requires a wider interval to capture the true population proportion. As a result, the precision of the estimate decreases as the margin of error increases.
Learn more about Confidence Intervals:
brainly.com/question/24131141
#SPJ11
A research center conducted a national survey about teenage behavior. Teens were asked whether they had consumed a soft drink in the past week. The following table shows the counts for three independent random samples from three major cities.
Answers
The given table represents the counts from three independent random samples taken from three major cities regarding whether teenagers consumed a soft drink in the past week.
By summing up the counts of teenagers who consumed a soft drink from all three cities and dividing it by the total number of teenagers surveyed, we can calculate the overall proportion. Dividing this proportion by the total number of teenagers and multiplying by 100 will give us the percentage of teenagers who consumed a soft drink.
For example, if the first city had a count of 150 teenagers who consumed a soft drink out of a total of 300 surveyed, the second city had 200 out of 400, and the third city had 180 out of 350, the overall proportion would be (150 + 200 + 180) / (300 + 400 + 350) = 530 / 1050. Multiplying this by 100, we find that approximately 50.48% of teenagers consumed a soft drink in the past week based on the combined sample.
Learn more about Dividing here:
https://brainly.com/question/15381501
#SPJ11
A research center conducted a national survey about teenage behavior. Teens were asked whether they had consumed a soft drink in the past week. The following table shows the counts for three independent random samples from major cities. Baltimore Yes 727 Detroit 1,232 431 1,663 San Diego 1,482 798 2,280 Total 3,441 1,406 4,847 No 177 904 Total (a) Suppose one teen is randomly selected from each city's sample. A researcher claims that the likelihood of selecting a teen from Baltimore who consumed a soft drink in the past week is less than the likelihood of selecting a teen from either one of the other cities who consumed a soft drink in the past week because Baltimore has the least number of teens who consumed a soft drink. Is the researcher's claim correct? Explain your answer. (b) Consider the values in the table. (i) Baltimore Detroit San Diego 0 0.1 0.9 1.0 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Relative Frequency of Response (ii) Which city had the smallest proportion of teens who consumed a soft drink in the previous week? Determine the value of the proportion. (c) Consider the inference procedure that is appropriate for investigating whether there is a difference among the three cities in the proportion of all teens who consumed a soft drink in the past week. (i) Identify the appropriate inference procedure. (ii) Identify the hypotheses of the test.
The owner of the Good Deals Store opens a new store across town. For the new store, the owner estimates that, during business hours, an average of 90 shoppers
Answers
The correct option is (A) 60 as the estimated average number of shoppers in the original store at any time is 45.
What is an average?In layman's terms, an average is a single number chosen to represent a set of numbers, usually the sum of the numbers divided by the number of numbers in the set. The average of the numbers 2, 3, 4, 7, and 9 is 5, for example.To find the estimated average number of shoppers in the original store at any time:
In the new store, the manager estimates that an average of 90 shoppers per hour enter the store, which is equivalent to 1.5 shoppers per minute. The manager also estimates that each shopper stays in the store for an average of 12 minutes. Thus, by Little’s law, there are, on average, N=rt = (1.5)(12) = 18 shoppers in the new store at any time. This is (45-18)/45 × 100 = 60 percent less than the average number of shoppers in the original store at any time.Therefore, the correct option is (A) 60 as the estimated average number of shoppers in the original store at any time is 45.
Know more about averages here:
https://brainly.com/question/20118982
#SPJ4
The complete question is given below:
The owner of the Good Deals Store opens a new store across town. For the new store, the owner estimates that, during business hours, an average of 90 shoppers per hour enter the store and each of them stays an average of 12 minutes. The average number of shoppers in the new store at any time is what percent less than the average number of shoppers in the original store at any time?
(A) 60
(B) 70
(C) 80
(D) 50
the product of a number and 5