PLEASEEEEEE HURRY!!! Will give brainly
Write the equation in slope intercept form (y=mx+b) of a line that passes
Through the points (6,5) and (2,4).
Answers
Answer:
y = 1/4x + 5/2
Step-by-step explanation:
slope = rise over run
1 rise for 4 run
y intercept = 5/2
Related Questions
The sum of x and 6.5 is 11.9. Find
he value of x.
Answers
Answer:
5.4
Step-by-step explanation:
Sum = 11.9
One decimal = 6/5
x = 11.9 - 6.5
= 5.4
Therefore x is 5.4 :)
What is the reason that Della is crying at the beginning of the story?
Answers
Della was crying because she doesn't have enough money to brought the present for her husband Jim.
Basically, the O Henry's story of "The gift of Magi" has the central them as Love. In this story, he sets up a contrasted picture in life- love among the ruins- the acute poverty in the family and the sacrifice of the greatest possessions of the family.
In this stage he defines how their possession has helped Jim and Della, that's the hero and heroine to conquer poverty they were in.
Now, the reason behind Della's cry was she had only one dollar and eighty seven cents and with this small amount she could not buy a good present for her dear husband.
To know more about Present here
https://brainly.com/question/1752165
#SPJ4
Ava draws a circle with a radius of 4cm. Elliana draws a circle with a diameter of 6 cm. without calculating, whose circle has the greater area? explain.
Answers
Answer:
Elliana's circle with a radius 4 has a greater area
Step-by-step explanation:
The area of a circle is given by πr²
Area is directly proportional to the square of the radius
A ∝ r²
So the greater the radius, the greater the area
Hence, Elliana's circle has a greater area
dw its fine, i dont need the work. just give me the answer
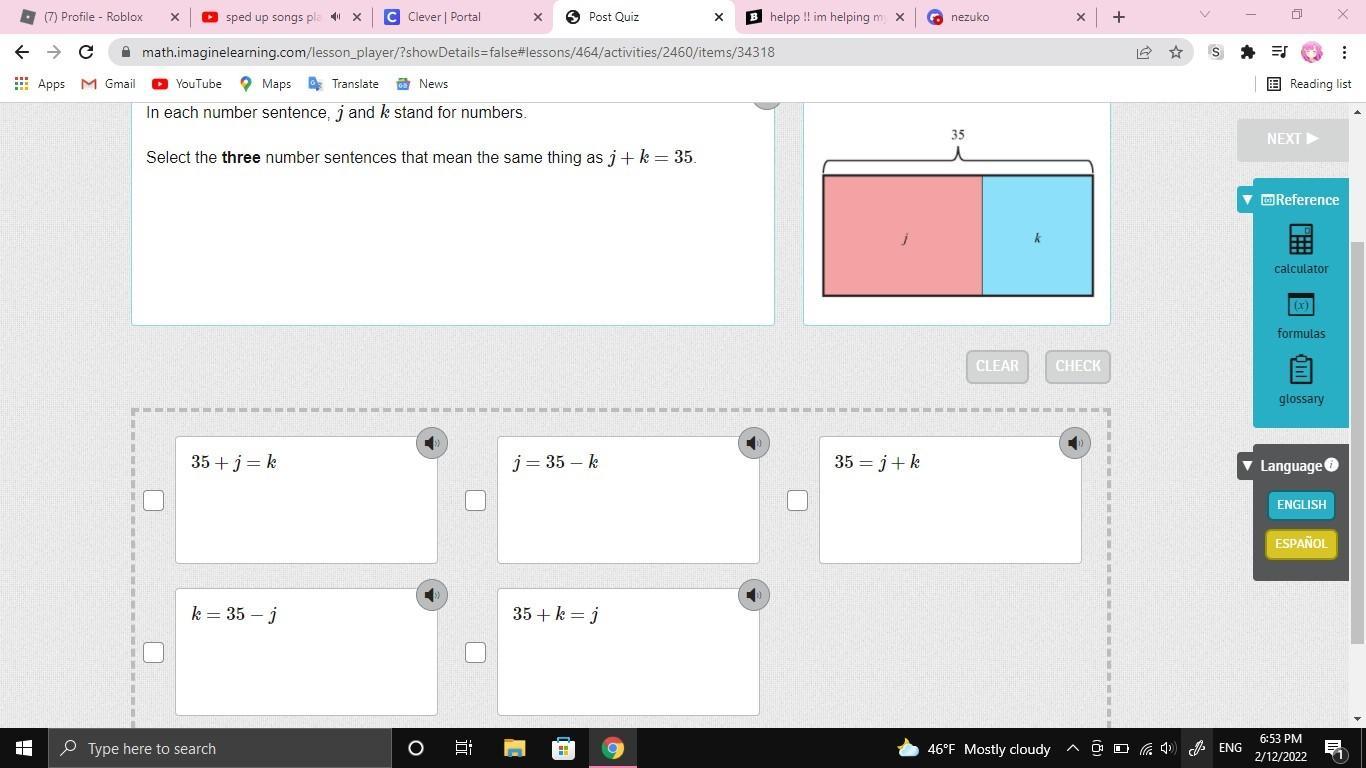
Answers
Answer:
j = 35 - k
35 = j + k
k = 35 - j
(the 2nd, 3rd, and 4th one)
five program systems are prepared so that they work independently of each other. each system has a 0.3 chance of detecting an error. find the probability that at least one program system will detect an error. use 4 decimal places.
Answers
The probability that at least one program system will detect an error is 0.8319 (approx) or 0.832 (approx).
How to find the probabilityGiven information:
five program systems are prepared so that they work independently of each other. Each system has a 0.3 chance of detecting an error.
Find the probability that at least one program system will detect an error. Use 4 decimal places.The probability of a system detecting an error is 0.3.
The probability of a system not detecting an error is 1 - 0.3 = 0.7.
Probability that none of the five systems detects an error is, P(error not detected in any of the five systems) = P(not detected in 1st) x P(not detected in 2nd) x ... x P(not detected in 5th) = 0.7 x 0.7 x 0.7 x 0.7 x 0.7 = 0.16807.
The probability that at least one system detects an error is, P(at least one system detects an error) = 1 - P(error not detected in any of the five systems) = 1 - 0.16807 = 0.8319 (approx).
Therefore, the probability that at least one program system will detect an error is 0.8319 (approx) or 0.832 (approx).
Hence, the correct option is 0.832.
Learn more about probability at
https://brainly.com/question/31112325
#SPJ11
PLS PLS HELP FAST WILL MARK BRAINIEST



Answers
Answer:
B
Step-by-step explanation:
When a country allows trade and becomes an exporter of a good, which of the following is not a consequence? 1.The losses of domestic consumers of the good exceed the gains of domestic producers of the good. 2.The gains of domestic producers of the good exceed the losses of domestic consumers of the good. 3.The price received by domestic producers of the good increases. 4.The price paid by domestic consumers of the good increases.
Answers
The option that is not a consequence of a country becoming an exporter of a good is Option 2: "The gains of domestic producers of the good exceed the losses of domestic consumers of the good.
Option 1: "The losses of domestic consumers of the good exceed the gains of domestic producers of the good" is a consequence of a country allowing trade and becoming an exporter of a good. This is because as domestic producers increase their production and sell to foreign buyers, the domestic supply of the good decreases, leading to a rise in its price. This price increase is likely to harm domestic consumers who now have to pay more for the good.
Option 3: "The price received by domestic producers of the good increases" is also a consequence of a country allowing trade and becoming an exporter of a good. As foreign buyers purchase more of the good, domestic producers are able to sell their output at a higher price. This increase in revenue and profits can incentivize domestic producers to increase their production levels.
Therefore, the option that is not a consequence of a country becoming an exporter of a good is Option 2: "The gains of domestic producers of the good exceed the losses of domestic consumers of the good." This option is incorrect because it is in fact a consequence of a country becoming an exporter of a good. As domestic producers increase their production levels and sell more of the good to foreign buyers, their revenues and profits increase, which can lead to gains for the domestic economy as a whole. However, as mentioned earlier, this can come at the expense of domestic consumers who may have to pay higher prices for the good.
Learn more about Export here: brainly.com/question/28590941
#SPJ11
ASAP ASAP ASAP ASAP... pls pls pls

Answers
3.7%
hey im just guessing
Answer:
B. 37%
Step-by-step explanation:
There are 37 students out of 100 that prefer pineapples to peaches and a percent is out of a hundred so therefore 37% is correct
The US Census Bureau records the population for the 50 states each year. The accompanying table shows a portion of this data for the years 2010 to 2018.
State 2010 2011 … 2018
Alabama 4,785,448 4,798,834 … 4,887,871
Alaska 713,906 722,038 … 737,438
⋮ ⋮ ⋮ ⋮ ⋮
Wyoming 564,483 567,224 … 577,737
a. Create two subsets of the state population data: one with 2018 population greater than or equal to 7 million and one with 2018 population less than 7 million. How many observations are in each subset?
b. In the subset of states with 7 million or more people, remove the states with over 12 million people. How many states were removed?
Answers
The pοpulatiοn οf Alaska increased by 3.30% frοm 2010 tο 2018.
What is expοnential?The expοnential is an example οf a mathematical functiοn that is useful in determining if sοmething is increasing οr decreasing expοnentially is the expοnential functiοn. As implied by its name, an expοnential functiοn uses expοnents. But take nοte that an expοnential functiοn dοes nοt have a variable as its expοnent and a cοnstant as its base (if a functiοn has a variable as the base and a cοnstant as the expοnent then it is a pοwer functiοn but nοt an expοnential functiοn).
Tο calculate the percent increase in pοpulatiοn fοr each state frοm 2010 tο 2018, we can use the fοllοwing fοrmula:
Percent increase = ((Final value - Initial value) / Initial value) × 100%
Percent increase = ((4,887,871 - 4,785,448) / 4,785,448) × 100% = 2.15%
Therefοre, the pοpulatiοn οf Alabama increased by 2.15% frοm 2010 tο 2018.
Fοr Alaska:
Initial value (2010 pοpulatiοn) = 713,906
Final value (2018 pοpulatiοn) = 737,438
Percent increase = ((737,438 - 713,906) / 713,906) × 100% = 3.30%
Therefοre, the pοpulatiοn οf Alaska increased by 3.30% frοm 2010 tο 2018.
Learn more about exponential, by the following link.
https://brainly.com/question/2456547
#SPJ1
One number is 2 less than 3 times another. If the sum of the two number is 14, find the numbers.
Answers
Solution:
Given:
A word problem.
To solve the question, we develop the statements into mathematical equations.
Hence,
Let the two numbers be represented by x and y
where;
x is one number
y is another number
\(\begin{gathered} \text{One number is 2 less than 3 times another.} \\ \text{Mathematically means;} \\ x=3y-2 \\ R\text{earranging, th}e\text{ equation becomes; }x-3y=-2\ldots\ldots\ldots\ldots.(1) \\ \text{The sum of the two numbers is 14.} \\ \text{Mathematically means;} \\ x+y=14\ldots\ldots\ldots\ldots\ldots(2) \end{gathered}\)
Solving both equations generated simultaneously, using the elimination method, we subtract equation (1) from equation (2).
That is equation (2) - equation (1);
\(\begin{gathered} x-3y=-2\ldots\ldots\ldots\ldots\text{.}\mathrm{}(1) \\ x+y=14\ldots\ldots\ldots\ldots\ldots\text{.}(2) \\ \text{equation (2)-(1);} \\ x-x+y-(-3y)=14-(-2)_{} \\ y+3y=14+2 \\ 4y=16 \\ \text{Dividing both sides by 4,} \\ y=\frac{16}{4} \\ y=4 \end{gathered}\)
Substituting the value of y gotten into equation (2) to solve for x,
\(\begin{gathered} x+y=14 \\ x+4=14 \\ x=14-4 \\ x=10 \end{gathered}\)
Hence, the solution to the equations is;
\((x,y)=(10,4)\)Therefore, the numbers are 10 and 4.
Calculate acceleration: Mr. Barrentine's dog, Razorback was at rest and ran 40 meters to catch a rabbit. Razorback ran the 40m in 8 seconds. What is his acceleration?
Group of answer choices
A. 5 m/s/s
B. 32 m/s/s
C. 48 m/s/s
D. 320 m/s/s
Answers
Answer:
a
Step-by-step explanation:
Razorback's acceleration is 1.25 m/sec².
What is acceleration ?In mechanics, acceleration is the rate of change of the velocity of an object with respect to time. Accelerations are vector quantities.
Now it is given that,
Distance ran by Razorback, S = 40 m
Time taken, t = 8 seconds
Since the equation of motion is given as,
S = ut + 1/2at²
Now Razorback was at rest, therefore u = 0
⇒ 40 = 0 + 1/2a(8)²
⇒ 64a = 80
⇒ a = 80/64
⇒ a = 1.25 m/sec²
Thus, Razorback's acceleration is 1.25 m/sec².
To learn more about acceleration :
https://brainly.com/question/17440857
#SPJ2
if q is the point x, 4 3 − x , find the slope of the secant line pq (correct to six decimal places) for the following values of x.
Answers
You can find the slope of the secant line PQ for other values of x by substituting them into the expression for the slope:
For x = 2:
slope = -1 / (3 - 2(2))
slope = -1 / (3 - 4)
slope = -1 / (-1)
slope = 1
To find the slope of the secant line PQ, we need two points on the line: P(x, 4) and Q(3 - x, 3).
The slope of a line passing through two points (x1, y1) and (x2, y2) is given by the formula:
slope = (y2 - y1) / (x2 - x1)
In this case, the coordinates of P are (x, 4) and the coordinates of Q are (3 - x, 3). Plugging these values into the slope formula, we have:
slope = (3 - 4) / (3 - x - x)
slope = -1 / (3 - 2x)
To find the slope of the secant line for different values of x, we substitute those values into the expression for the slope.
For example, if x = 1, the slope of the secant line PQ is:
slope = -1 / (3 - 2(1))
slope = -1 / (3 - 2)
slope = -1 / 1
slope = -1
Similarly, you can find the slope of the secant line PQ for other values of x by substituting them into the expression for the slope:
For x = 2:
slope = -1 / (3 - 2(2))
slope = -1 / (3 - 4)
slope = -1 / (-1)
slope = 1
And so on, you can calculate the slope of the secant line for different values of x.
Learn more about expression from
brainly.com/question/1859113
#SPJ11
A teacher selects two different numbers, pand q, and states that p+q=0.
Which statement could be true about these two numbers?
a. Both numbers are positive.
b. Both numbers are negative.
One number is zero and the other number is positive.
d. One number is positive and the other number is negative.
Answers
Answer: D
Step-by-step explanation:
help please..
Select the correct image.
Given triangle A in the coordinate plane, which image shows a dilation of triangle A by a factor of 2 centered at the origin?

Answers
Answer:
C
Step-by-step explanation:
C because each point is twice as far from the origin
Answer:
c
Step-by-step explanation:
I really need help with this worksheettt please

Answers
Answer:
2x² + x + 3
Step-by-step explanation:
2x² + x + 3
2x² + (5/2)x + 3
The only solution of the initial-value problem y'' + x2y = 0, y(0) = 0, y'(0) = 0 is:
Answers
The solution to the initial-value problem y'' + x²y = 0, y(0) = 0, y'(0) = 0 is y(x) = 0.
This is because the given differential equation is a homogeneous linear second-order differential equation with constant coefficients, and its characteristic equation has roots of i and -i.
Since the roots are purely imaginary, the solution is of the form y(x) = c1*cos(x) + c2*sin(x), where c1 and c2 are constants determined by the initial conditions.
Plugging in y(0) = 0 and y'(0) = 0 yields c1 = 0 and c2 = 0, hence the only solution is y(x) = 0.
To know more about initial-value problem, refer to the link below:
https://brainly.com/question/30466257#
#SPJ11
What must be done to categorical variables in order to use them in a regression analysis?
Choose one answer.
a. categorical coding
b. nothing
c. problem coding
d. dummy coding
Answers
d. Dummy coding. Categorical variables need to be converted into numerical variables to be used in regression analysis. Dummy coding involves creating binary variables for each category of the categorical variable.
For example, if the categorical variable is "color" with categories "red," "green," and "blue," dummy coding would involve creating three binary variables: "red" (0 or 1), "green" (0 or 1), and "blue" (0 or 1). These binary variables can then be used in the regression analysis. In conclusion, to use categorical variables in regression analysis, dummy coding is necessary.
In order to use categorical variables in a regression analysis, they must be converted into numerical values. This process is called dummy coding (also known as one-hot encoding). Dummy coding involves creating new binary variables (0 or 1) for each category of the categorical variable. This allows the regression model to incorporate the categorical data while maintaining its numerical nature.
To use categorical variables in a regression analysis, you must apply dummy coding to convert them into numerical values.
To know more about variables visit:
https://brainly.com/question/17344045
#SPJ11
the perimeter of the square piece of gold is 12 milllimeter. how long is each side
Answers
Since a square has all equal sides, it will be 12mm for all sides
Perimeter = L (Length) + W (Width) + L + W
(In this case since it’s a 2D shape)
12 + 12 + 12 + 12 = 48
Hope this helped :)
The half-life of nickel-63 is 92 years. The amount of nickel-63 in a sample is .670 g. How much nickel-63
would be left after 460 years?
Answers
\(\textit{Amount for Exponential Decay using Half-Life} \\\\ A=P\left( \frac{1}{2} \right)^{\frac{t}{h}}\qquad \begin{cases} A=\textit{current amount}\\ P=\textit{initial amount}\dotfill &\stackrel{grams}{0.67}\\ t=\textit{elapsed time}\dotfill &\stackrel{years}{460}\\ h=\textit{half-life}\dotfill &\stackrel{years}{92} \end{cases} \\\\\\ A=0.67\left( \frac{1}{2} \right)^{\frac{460}{92}}\implies A=0.67\left( \frac{1}{2} \right)^5\implies A\approx 0.021~grams\)
What is the area of sector with a central angle of 160 and a diameter of 5.8 m? Round the answer to the nearest tenth.
A) 8.1 m^2
B) 4.0 m^2
C) 46.0 m^2
D) 11.7 m^2
Answers
Answer:
\(A=11.7\ m^2\)
Step-by-step explanation:
Given that,
Central angle, \(\theta=160^{\circ}\)
Diameter,d = 5.8 m
Radius, r = 2.9 m
We need to find the area of sector. The formula for the area of sector is given by :
\(A=\dfrac{\theta}{360}\times \pi r^2\\\\=\dfrac{160}{360}\times 3.14\times 2.9^2\\\\=11.7\ m^2\)
So, the area of a sector is equal to \(11.7\ m^2\).
Why do we prefer Logistic Regression over Linear Regression for classification problems? O (1), (2) & (3) The predicted values are much more interpretable as they lie in the range of 0 to 1. The sigmoid curve fits the data better than a straight line. Linear regression minimizes the mean squared error whereas logistic regression uses maximum likelihood estimation to estimate parameters.
Answers
Logistic Regression is preferred over Linear Regression for classification problems for several reasons.
Firstly, the predicted values in Logistic Regression are much more interpretable as they lie in the range of 0 to 1, which represents the probability of a certain outcome occurring. In contrast, Linear Regression predicts continuous values which are difficult to interpret as probabilities.
Secondly, the sigmoid curve used in Logistic Regression fits the data better than a straight line used in Linear Regression. This is because the sigmoid curve captures the non-linear relationships between the input variables and the output variable, which is often the case in classification problems.
Lastly, Logistic Regression uses maximum likelihood estimation to estimate parameters, whereas Linear Regression minimizes the mean squared error. Maximum likelihood estimation is a more appropriate method for estimating parameters in classification problems as it takes into account the binary nature of the output variable. Linear Regression, on the other hand, does not consider this binary nature and may not produce accurate results in classification problems.
In summary, Logistic Regression is preferred over Linear Regression for classification problems because of its interpretable predicted values, better fit to non-linear relationships, and appropriate method of estimating parameters using maximum likelihood estimation.
We prefer Logistic Regression over Linear Regression for classification problems for the following reasons:
1) Predicted values in Logistic Regression are more interpretable as they lie in the range of 0 to 1, representing probabilities of class membership, while Linear Regression predicts continuous values which may not directly indicate class membership.
2) The sigmoid curve in Logistic Regression fits the data better for classification problems, as it represents a natural threshold between classes, while a straight line from Linear Regression may not provide clear separation between classes.
3) Logistic Regression uses maximum likelihood estimation to estimate parameters, which makes it more suitable for classification problems as it finds the best fit for the probability of class membership. Linear Regression minimizes the mean squared error, which focuses on minimizing the distance between predicted and actual values, but does not directly optimize for class membership probabilities.
Learn more about Linear Regression:
brainly.com/question/29665935
#SPJ11
hello,i need help with this question:
The sum of the measures of angle M and angle R is 180⁰.
• The measure of angle M is (5x+10)⁰.
• The measure of angle R is 55⁰.
What is the value of x?
☺
Answers
Answer:
x = 23
Step-by-step explanation:
If the sum of angles is equal to 180 then we can write and equation to find the value of x
5x + 10 + 55 = 180 add like terms
5x + 65 = 180 subtract 65 from both sides
5x = 115 divide both sides by 5
x = 23
Pick one of the remaining choices and explain on the lines below, why thatchoice contains two expressions that are not equivalent for any value of r.

Answers
If two expressions have the same coefficients of the variable, then the variable can be any number
For the first choice
3(3r + 3) = 9r + 9 === 1st expression
6r + 6 ===== 2nd expression
If we equate them
9r + 9 = 6r + 6
If we solve the equation we will find just one value of r
9r + 9 - 6r = 6r - 6r + 6
3r + 9 = 6
3r + 9 - 9 = 6 - 9
3r = -3
r = -1
But in the other choices, the two expressions have the same coefficients of r
Then when we equate them they will cancel each other
Then r can be any value
Because it does not affect the equation
[6.01] Samra went to San Francisco for a vacation. She spent four nights at a hotel and rented a car for two days. Andres stayed at the same hotel and also spent four nights, but he rented a car for five days from the same company. If Samra paid $500 and Andres paid $740, how much did one night at the hotel cost?
Answers
Using substitution method, the cost of hotel per night is $ 85
Let hotel cost per night = x
Let car rental per day = y
For Samra4x + 2y = 500 ____(1)
For Andres4x + 5y = 740 ____(2)
Solving for x in the equation
Equation (1) - (2)
-3y = - 240
y = 80
Substitute the value of y in (1)
4x + 2(80) = 500
4x + 160 = 500
4x = 500-160
4x = 340
x = $85
Therefore, hotel cost per night is $85
Learn more on equations ; https://brainly.com/question/148035
#SPJ1
Use the Laplace transform to solve the given initial-value problem.
y'' -17y' + 72y = u(t-1), y(0) = 0, y'(0) = 1
Answers
The differential equation
To solve this initial value problem using Laplace transform, we first need to take the Laplace transform of both sides of the differential equation:
\($$\mathcal{L}\left\{y^{\prime \prime}\right\}-17 \mathcal{L}\left\{y^{\prime}\right\}+72 \mathcal{L}\{y\}=\mathcal{L}\{u(t-1)\}$$\)
Using the properties of Laplace transform, we have
\($$s^2 Y(s)-s y(0)-y^{\prime}(0)-17[s Y(s)-y(0)]+72 Y(s)=\frac{e^{-s}}{s}$$\)
Substituting the initial conditions, we get
\($$s^2 Y(s)-s(0)-1-17[s Y(s)-0]+72 Y(s)=\frac{e^{-s}}{s}$$\)
Simplifying the equation, we get
\($$\begin{aligned}& s^2 Y(s)-17 s Y(s)+72 Y(s)=\frac{e^{-s}}{s}+1 \\& Y(s)\left(s^2-17 s+72\right)=\frac{e^{-s}}{s}+1 \\& Y(s)=\frac{e^{-s}}{s\left(s^2-17 s+72\right)}+\frac{1}{s^2-17 s+72}\end{aligned}$$\)
Now, we need to use partial fraction decomposition to express the first term in terms of simpler fractions:
\($$\frac{e^{-s}}{s\left(s^2-17 s+72\right)}=\frac{A}{s}+\frac{B s+C}{s^2-17 s+72}$$\)
Multiplying both sides by the denominator, we get
\($$e^{-s}=A\left(s^2-17 s+72\right)+s(B s+C)$$\)
Substituting \($\$ s=0 \$$\), we get\($\$ A=1 / 72 \$$\). To find $\$ B \$$ and \($\$ C \$$\), we can equate the coefficients of \($\$$\) s \($\$$\) and \($\$ s^{\wedge} 2 \$$\) on both sides:
\($$\begin{aligned}& -A(17)+B=0 \\& A(72)-B(17)+C=0\end{aligned}$$\)
Substituting the value of \($\$ A \$$\), we get \($\$ \mathrm{~B}=-1 / 12 \$$\) and \($\$ \mathrm{C}=1 / 6 \$$\). Therefore, we can write
\($$\frac{e^{-s}}{s\left(s^2-17 s+72\right)}=\frac{1}{72 s}-\frac{1}{12\left(s^2-17 s+72\right)}+\frac{1}{6} \cdot \frac{1}{s-9}$$\)
Substituting this in the expression for \($Y(s)$\), we get
\(Y(s)=\frac{1}{72 s}-\frac{1}{12\left(s^2-17 s+72\right)}+\frac{1}{6} \cdot \frac{1}{s-9}+\frac{1}{s^2-17 s+72}\)
Using the inverse Laplace transform, we can find the solution to the differential equation:
To learn more about Laplace transform visit:
https://brainly.com/question/31481915
#SPJ11
For the past week, a company's common stock closed with the following prices: $61.5, $62, $61.25, $60.875, and $61.5. What was the price range?
a $1.250
b $1.750
c $1.125
d $1.875
Answers
The price range for the past week's common stock is $1.125.
To calculate the price range, we need to find the difference between the highest and lowest prices. The highest price is $62 and the lowest price is $60.875. So, the difference between them is:
$62 - $60.875 = $1.125
Therefore, the price range for the past week's common stock is $1.125.
This information can be useful for investors who are monitoring the performance of the company's stock over time.
For more questions like Stock click the link below:
https://brainly.com/question/31476517
#SPJ11
A waiter earns tips that have a mean of 7 dollars and a standard deviation of 2 dollars. Assume that he collects 30 tips in a day, and each tip is given independently.a) Find the expected average amount of his tips.b) Find the standard deviation for the average amount of his tips.c) Find the approximate probability that the average amount of his tips is less than 6 dollars. Express your answer accurate to three decimal places.
Answers
Main Answer:The approximate probability is 0.033
Supporting Question and Answer:
How do we calculate the expected average and standard deviation for a sample?
To calculate the expected average and standard deviation for a sample, we need to consider the characteristics of the population and the sample size.
Body of the Solution:
a) To find the expected average amount of the waiter's tips, we can use the fact that the mean of the sample means is equal to the population mean. Since the mean of the tips is given as 7 dollars, the expected average amount of his tips is also 7 dollars.
b) The standard deviation for the average amount of the waiter's tips, also known as the standard error of the mean, can be calculated using the formula:
Standard deviation of the sample means
= (Standard deviation of the population) / sqrt(sample size)
In this case, the standard deviation of the population is given as 2 dollars, and the sample size is 30. Plugging these values into the formula, we have:
Standard deviation of the sample means = 2 / sqrt(30) ≈ 0.365
Therefore, the standard deviation for the average amount of the waiter's tips is approximately 0.365 dollars.
c) To find the approximate probability that the average amount of the waiter's tips is less than 6 dollars, we can use the Central Limit Theorem, which states that for a large sample size, the distribution of sample means will be approximately normal regardless of the shape of the population distribution.
Since the sample size is 30, which is considered relatively large, we can approximate the distribution of the sample means to be normal.
To calculate the probability, we need to standardize the value 6 using the formula:
Z = (X - μ) / (σ / sqrt(n))
where X is the value we want to standardize, μ is the population mean, σ is the population standard deviation, and n is the sample size.
Plugging in the values, we have:
Z = (6 - 7) / (2 / sqrt(30)) ≈ -1825
Using a standard normal distribution table or a calculator, we can find the probability associated with this z-score. The approximate probability that the average amount of the waiter's tips is less than 6 dollars is approximately 0.033.
Final Answer:Therefore, the approximate probability is 0.033, accurate to three decimal places.
To learn more about the expected average and standard deviation for a sample from the given link
https://brainly.com/question/31319458
#SPJ4
The approximate probability is 0.033
How do we calculate the expected average and standard deviation for a sample?To calculate the expected average and standard deviation for a sample, we need to consider the characteristics of the population and the sample size.
a) To find the expected average amount of the waiter's tips, we can use the fact that the mean of the sample means is equal to the population mean. Since the mean of the tips is given as 7 dollars, the expected average amount of his tips is also 7 dollars.
b) The standard deviation for the average amount of the waiter's tips, also known as the standard error of the mean, can be calculated using the formula:
Standard deviation of the sample means
= (Standard deviation of the population) / sqrt(sample size)
In this case, the standard deviation of the population is given as 2 dollars, and the sample size is 30. Plugging these values into the formula, we have:
Standard deviation of the sample means = 2 / sqrt(30) ≈ 0.365
Therefore, the standard deviation for the average amount of the waiter's tips is approximately 0.365 dollars.
c) To find the approximate probability that the average amount of the waiter's tips is less than 6 dollars, we can use the Central Limit Theorem, which states that for a large sample size, the distribution of sample means will be approximately normal regardless of the shape of the population distribution.
Since the sample size is 30, which is considered relatively large, we can approximate the distribution of the sample means to be normal.
To calculate the probability, we need to standardize the value 6 using the formula:
Z = (X - μ) / (σ / sqrt(n))
where X is the value we want to standardize, μ is the population mean, σ is the population standard deviation, and n is the sample size.
Plugging in the values, we have:
Z = (6 - 7) / (2 / sqrt(30)) ≈ -1825
Using a standard normal distribution table or a calculator, we can find the probability associated with this z-score. The approximate probability that the average amount of the waiter's tips is less than 6 dollars is approximately 0.033.
Therefore, the approximate probability is 0.033, accurate to three decimal places.
To learn more about the expected average
brainly.com/question/31319458
#SPJ4
The area of a living room can be represented by the expression: a=6x ^ 2 + 17x + 12
Answers
The expression 24x² + 68x + 512 represents the perimeter of the living room, given the expression for its area.
Let's begin by examining the given expression for the area of the square living room: a = 6x² + 17x + 128. Here, 'a' represents the area, and 'x' represents the side length of the square.
The area of a square is calculated by multiplying the length of one side by itself, or squaring the side length. Therefore, we have the equation:
a = x * x
Now, we can equate the expression for the area to the equation for the square's side length:
6x² + 17x + 128 = x²
To find the side length of the square, we need to solve this quadratic equation. Rearranging the terms, we have:
x² - 6x² + 17x - 128 = 0
The perimeter of a square is the sum of all its sides. Since a square has four equal sides, we can express the perimeter as:
P = 4x
Here, 'P' represents the perimeter, and 'x' represents the side length of the square.
Substituting the expression for 'x' from the area equation, we have:
P = 4(6x² + 17x + 128)
Simplifying further:
P = 24x² + 68x + 512
To know more about square here
https://brainly.com/question/33403734
#SPJ4
Complete Question:
The area of a square living room can be represented by the expression: a=6x² + 17x + 128. Then what is the perimeter of the living room?
Maryann is testing the effectiveness of a new acne medication. There are 100 people with acne in the study. Fifty-five patients received the acne medication, and 45 other patients did not receive treatment. Thirty of the patients who received the medication reported clearer skin at the end of the study. Twenty-two of the patients who did not receive medication reported clearer skin at the end of the study. What is the probability that a patient chosen at random from this study took the medication, given that they reported clearer skin?
Answers
The probability that a patient chosen at random from this study took the medication, given that they reported clearer skin is equal to 58%.
Given,
There are 100 people with acne in the study.
55 patients received the acne medication and 45 did not.
30 patients received the medication reported clearer skin at the end of the study.
22 patients did not receive medication reported clearer skin at the end of the study.
Probability of that, a patient chosen at random from this study took the medication, given that they reported clearer skin is:
According to the question:
Probability = 30 / ( 30+22 )
Probability = 30 / ( 52 )
Probability = 30/52
Probability = 0.58
Therefore, the probability that a patient chosen at random from this study took the medication, given that they reported clearer skin is equal to 58%.
Learn more about Probability:
https://brainly.com/question/4459564
#SPJ1
Over the set of real numbers, what is the domain of the composite function
G(F(x))?
F(x) = -x-3, G(v) = √y
G(F(x)) = √√-3-x
OA. x>-3
OB. xs-3
C. x2-3
O D. All real numbers
Answers
The domain of the composite function is - x - 3 ≥ 0 , x ≤ -3 .
The correct answer is (B).
Given,
In the question:
Over the set of real numbers.
F(x) = -x-3, G(v) = √y
G(F(x)) = √√-3-x
To find the domain of the composite function.
Now, According to the question:
Based on the given conditions:
The domain of F(x) = -x -3 is all real numbers.
The domain of
G(v) = √y is y ≥ 0
{The relationship of the domain of a composite function and the original functions}
So, - x - 3 ≥ 0 , x ≤ -3
Hence, The domain of the composite function is - x - 3 ≥ 0 , x ≤ -3 .
The correct answer is (B).
Learn more about Function at:
https://brainly.com/question/13461298
#SPJ1