True or False. When FTP users authenticate with an FTP server, the sign-in process can be decoded by a protocol analyzer or network sniffer software.
Answers
The File Transfer Protocol is commonly called FTP. FTP users authenticate with an FTP server, the sign-in process can be decoded by a protocol analyzer or network sniffer software is a true statement.
There are some element that often specifies the authentication settings for FTP sites. The authentication settings are known to be wired or configured at only the site-level. They can also be configured per URL.The File Transfer Protocol (FTP) is known simply as a standard communication protocol that is often employed for the movement of computer files from a server to a client using a computer network.
It uses the client–server model architecture via different control and data connections between the client and the server.
Learn more from
https://brainly.com/question/20602197
Related Questions
In the future, will training
and education become
more or less desirable?
Answers
To young children and students it'll be less desirable as they just want to play, I mean this is a natural characteristic of children so there's nothing to blame on them, but to young adults like college students and also parents, it's likely to be more desirable as they want their children to have a bright future through studying hard and landing themselves in good jobs. however, to some parents they might find it less desirable as they do not want their children to have pressure or and form of stress since it might still be the strawberry generation in the future.
Which of the following is a factor that can cause poor network performance? (Choose all that apply.)
a. Poor network design
b. Private IP addresses
c. Poor traffic management
d. Server clusters
Answers
The factor that can cause poor network performance
a. Poor network design
c. Poor traffic management
What are the reasons for poor network performance?Network problems due to by faulty hardware (such as routers, switches and firewalls). They can also be caused by unexpected usage patterns, such as network bandwidth spikes that exceed the bandwidth allocated to users, or security breaches, hardware configuration changes, etc.
There are many reasons for poor network performance. Some network problems can be caused by faulty hardware (such as routers, switches, firewalls) and even unexpected usage patterns such as spikes in network bandwidth, application configuration changes or security breaches.
Factors affecting network performance
number of devices on the network. transmission average bandwidth. network traffic type. network latency. number of transmission errors.To know more about network performance, refer;
https://brainly.com/question/28590616
#SPJ1
Question 10 of 10
What information system would be most useful in determining what direction
to go in the next two years?
A. Decision support system
B. Transaction processing system
C. Executive information system
D. Management information system
SUBMIT
Answers
Answer: C. Executive information system
Explanation: The information system that would be most useful in determining what direction to go in the next two years is an Executive Information System (EIS). An EIS is designed to provide senior management with the information they need to make strategic decisions.
An Executive Information System (EIS) would be the most useful information system in determining what direction to go in the next two years. So, Option C is true.
Given that,
Most useful information about determining what direction to go in the next two years.
Since Executive Information System is specifically designed to provide senior executives with the necessary information and insights to support strategic decision-making.
It consolidates data from various sources, both internal and external, and presents it in a user-friendly format, such as dashboards or reports.
This enables executives to analyze trends, identify opportunities, and make informed decisions about the future direction of the organization.
EIS typically focuses on high-level, strategic information and is tailored to meet the specific needs of top-level executives.
So, the correct option is,
C. Executive information system
To learn more about Executive information systems visit:
https://brainly.com/question/16665679
#SPJ6
Although Python provides us with many list methods, it is good practice and very instructive to think about how they are implemented. Implement a Python methods that works like the following: a. count b. in: return True if the item is in the list c. reverse d. index: return -1 if the item is not in the list e. insert
Answers
Answer:
Here are the methods:
a) count
def count(object, list):
counter = 0
for i in list:
if i == object:
counter = counter + 1
return counter
b) in : return True if the item is in the list
def include(object, list):
for i in list:
if i == object:
return True
return False
c) reverse
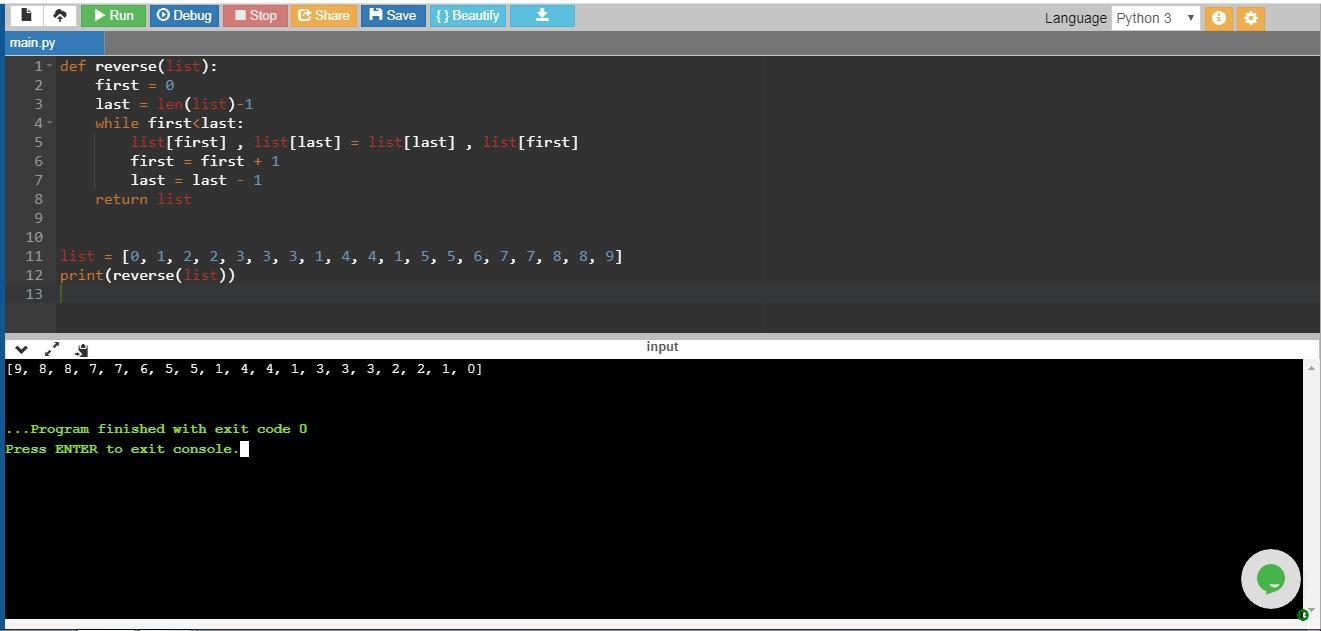
def reverse(list):
first = 0
last = len(list)-1
while first<last:
list[first] , list[last] = list[last] , list[first]
first = first + 1
last = last - 1
return list
d) index: return -1 if the item is not in the list
def index(object, list):
for x in range(len(list)):
if list[x] == object:
return x
return -1
e) insert
def insert(object, index, list):
return list[:index] + [object] + list[index:]
Explanation:
a)
The method count takes object and a list as parameters and returns the number of times that object appears in the list.
counter variable is used to count the number of times object appears in list.
Suppose
list = [1,1,2,1,3,4,4,5,6]
object = 1
The for loop i.e. for i in list iterates through each item in the list
if condition if i == object inside for loop checks if the item of list at i-th position is equal to the object. So for the above example, this condition checks if 1 is present in the list. If this condition evaluates to true then the value of counter is incremented to 1 otherwise the loop keeps iterating through the list searching for the occurrence of object (1) in the list.
After the complete list is moved through, the return counter statement returns the number of times object (i.e. 1 in the example) occurred in the list ( i.e. [1,1,2,1,3,4,4,5,6] ) As 1 appears thrice in the list so the output is 3.
b)
The method include takes two parameters i.e. object and list as parameters and returns True if the object is present in the list otherwise returns False. Here i have not named the function as in because in is a reserved keyword in Python so i used include as method name.
For example if list = [1,2,3,4] and object = 3
for loop for i in list iterates through each item of the list and the if condition if i == object checks if the item at i-th position of the list is equal to the specified object. This means for the above example the loop iterates through each number in the list and checks if the number at i-th position in the list is equal to 3 (object). When this if condition evaluates to true, the method returns True as output otherwise returns False in output ( if 3 is not found in the list). As object 3 is present in the list so the output is True.
c) reverse method takes a list as parameter and returns the list in reverse order.
Suppose list = [1,2,3,4,5,6]
The function has two variables i.e. first that is the first item of the list and last which is the last item of the list. Value of first is initialized to 0 and value of last is initialized to len(list)-1 where len(list) = 6 and 6-1=5 so last=5 for the above example. These are basically used as index variables to point to the first and last items of list.
The while loop executes until the value of first exceeds that of last.
Inside the while loop the statement list[first] , list[last] = list[last] , list[first] interchanges the values of elements of the list which are positioned at first and last. After each interchange the first is incremented to 1 and last is decremented to 1.
For example at first iteration:
first = 0
last = 5
list[0] , list[5] = list[5] , list[0]
This means in the list [1,2,3,4,5,6] The first element 1 is interchanged with last element 6. Then the value of first is incremented and first = 1, last = 4 to point at the elements 2 and 5 of the list and then exchanges them too.
This process goes on until while condition evaluates to false. When the loop breaks statement return list returns the reversed list.
d) The method index takes object and list as parameters and returns the index of the object/item if it is found in the list otherwise returns -1
For example list = [1,2,4,5,6] and object = 3
for loop i.e. for x in range(len(list)): moves through each item of the list until the end of the list is reached. if statement if list[x] == object: checks if the x-th index of the list is equal to the object. If it is true returns the index position of the list where the object is found otherwise returns -1. For the above examples 3 is not in the list so the output is -1
e) insert
The insert function takes as argument the object to be inserted, the index where the object is to be inserted and the list in which the object is to be inserted.
For example list = [0, 1, 2, 4, 5, 6] and object = 3 and index = 3
3 is to be inserted in list [1,2,4,5] at index position 3 of the list. The statement:
return list[:index] + [object] + list[index:]
list[:index] is a sub list that contains items from start to the index position. For above example:
list[:index] = [0, 1, 2]
list[index:] is a sub list that contains items from index position to end of the list.
list[index:] = [4, 5, 6]
[object] = [3]
So above statement becomes:
[0, 1, 2] + [3] + [4, 5, 6]
So the output is:
[0, 1, 2, 3, 4, 5, 6]




The programming interface for a legacy motor controller accepts commands as binary strings of variable lengths.
a. True
b. False
Answers
Answer:
The answer is "Option a"
Explanation:
The given question is incomplete, that's why its correct solution can be defined as follows:
The above-given question is the part of the Binary Autocomplete, in which this Autocomplete function would be a full word or sentence after just a few other letters were entered into the system. It approach improves text taking appropriate on smartphone devices of particular because every letter should not be written in such a single phrase.
What's the output of the following code?
var x = 10;
x = x + 4;
Console.log (“The value of x is "+x+"!");
O 14!
O The value of x is x!
O The value of x is 14
O The value of x is 14!
Answers
The answer should be "The value of x is 14!"
A detailed description is shown in the photo below. I wish you success!

some people do not use the internet because of their religious beliefs. Evaluate positive and negative impacts
Answers
Answer:
There are some individuals who refrain from using the internet due to their religious beliefs. While this is a personal decision, it can have both positive and negative impacts on their lives.
Positive impacts of not using the internet for religious reasons:Less exposure to negative content: Some religious individuals may choose to avoid the internet because they feel that it exposes them to too much negative content. By staying away from the internet, they can maintain a more positive outlook on life and avoid being exposed to negative influences.
More time for religious practices: By not using the internet, individuals may have more time to focus on their religious practices, such as prayer, meditation, or attending religious services. This can strengthen their spiritual connection and bring them closer to their faith.Greater face-to-face interaction: Without the internet, people may be more likely to engage in face-to-face interactions with others, including members of their religious community. This can foster a sense of community and belonging.
Negative impacts of not using the internet for religious reasons:Limited access to information: By not using the internet, individuals may miss out on important information related to their religious practices, as well as other aspects of their lives, such as news, education, and job opportunities.
Limited social connections: The internet provides a platform for people to connect with others who share their interests, including their religious beliefs. Without access to the internet, individuals may feel isolated and disconnected from others who share their faith.Limited opportunities for growth: The internet provides access to a wealth of resources, including educational materials and career opportunities. By not using the internet, individuals may miss out on opportunities for personal and professional growth.
In conclusion, while not using the internet for religious reasons may have some positive impacts, it can also have negative consequences. Ultimately, it is up to individuals to weigh the benefits and drawbacks of using the internet based on their personal beliefs and values.
State whether the data described below are discrete or continuous, and explain why. The durations of movies in seconds
Answers
Answer:
the data are continuous because the data can take any value in an interval.
Hey tell me more about your service
Answers
Answer:
look below!
Explanation:
please add more context and I’ll be happy to answer!
How can you ensure that the website you are using is secured?
A.
website begins with http://
B.
website begins with https:// and has a green padlock
C.
website doesn’t have any padlock icon
D.
website has a red padlock icon
Answers
A stack is a ___________________ data structure.
Answers
Answer:
A stack is a base data structure.
What is a word processing program? Give examples of word processing programs.
Answers
Answer:
A word processor, or word processing program, does exactly what the name implies. It processes words. It also processes paragraphs, pages, and entire papers. Some examples of word processing programs include Microsoft Word, WordPerfect (Windows only), AppleWorks (Mac only), and OpenOffice.org.
The NeedsMet rating is based on both the query and the result
Answers
It is TRUE to state that the NeedsMet rating is based on both the query and the result.
How is this so?The grade of Needs Met is based on both the question and the response. When awarding a Needs Met rating, you must carefully consider the query and user intent. The Page Quality rating slider is unaffected by the query. When providing a Page Quality rating to the LP, do not consider the query.
The Needs Met measure considers all aspects of "helpfulness," and many users consider low Page Quality results to be less useful than high Page Quality results. This should be reflected in your ratings. The HM [highly meets] grade should be assigned to sites that are useful, have high Page Quality, and are a good match for the query.
Learn more about query at:
https://brainly.com/question/25694408
#SPJ1
You see a picture of three people having fun in an IG post. Beneath the photo is a text about a prty. You wrongly assume this picture was taken at a prty when it was actually taken during a family dinner. This type of misunderstanding is an example of
Answers
From the information given this type of misunderstanding is an example of: Communication Barrier.
What are communication Barriers?Communication obstacles prohibit us from accurately receiving and accepting the messages used by others to transmit their information, thoughts, and ideas. Communication difficulties include information overload, selective perceptions, workplace gossip, semantics, gender disparities, and so on.
It is to be noted that the Assumption that you comprehend what the other person is saying is one of the most significant communication barriers. People frequently make assumptions based on their own experiences and interpretations. You don't always know you're not talking about the same subject.
Learn more about Communication Barrier:
https://brainly.com/question/8588667
#SPJ1
Answer:
error, i think.
Which of these is an example of a vertical standard? Please select all that apply. Excavation workers must be protected from cave-ins. When welding, a fire watch must be maintained for 30 minutes past the time of welding. Ladders must always extend three feet past the working surface. An iron worker is placing steel 30 feet up and is wearing a full body harness tied off to an anchor point with a lanyard. PPE is required to protect against face, hand, and eye injuries.
Answers
An example of a vertical standard (that is specific safety standard) from the list are:
Excavation workers must be protected from cave-ins. (Option A)When welding, a fire watch must be maintained for 30 minutes past the time of welding. (Option B)An ironworker is placing steel 30 feet up and is wearing a full body harness tied off to an anchor point with a lanyard (Option D)What is a Vertical Standard?
The majority of OSHA rules are horizontal in nature. That is, they apply to all employers, regardless of industry.
However, several OSHA requirements are vertical in nature. This indicates that they only apply to a single industry.
Vertical standards are applicable to certain industries or activities, procedures, situations, processes, means, techniques, equipment, or installations.
Vertical OSHA guidelines include the following:
OSHA's Construction Standards from 1926OSHA's Shipyard Standards from 1915OSHA 1910 Subpart R Special Businesses Regulations apply to pulp, paper, and paperboard mills, textile mills, sawmills, and other industries.Learn more about safety standards:
https://brainly.com/question/15371083
#SPJ1
Discuss what is dominance relationship
Answers
Answer:
dominance is a relationship between two alleles of a particular allele of a gene and their associated phenotypes.
The concept of dominance has recently attracted much interest in the context of skyline computation. Given an N dimensional data set s a point p is said to dominate q, I'd p is better than q in atheist one dimension and equal to or better than it remaining dimensions.
The government now requires physicians to store patient information in databases that are accessible in multiple locations by multiple people if they want to qualify for certain reimbursements. The rationale is that this will enable healthcare providers the ability to better serve their patients, as all will have access to the patients’ medical history. Many patients worry about compromised privacy and security, especially since these databases are accessible via the Internet. Should patients be allowed to opt-out of these data collection systems or should it remain a government mandate? Provide justification for your answer.
Answers
Answer:
.
Explanation:

A Quicksort (or Partition Exchange Sort) divides the data into 2 partitions separated by a pivot. The first partition contains all the items which are smaller than the pivot. The remaining items are in the other partition. You will write four versions of Quicksort:
• Select the first item of the partition as the pivot. Treat partitions of size one and two as stopping cases.
• Same pivot selection. For a partition of size 100 or less, use an insertion sort to finish.
• Same pivot selection. For a partition of size 50 or less, use an insertion sort to finish.
• Select the median-of-three as the pivot. Treat partitions of size one and two as stopping cases.
As time permits consider examining additional, alternate methods of selecting the pivot for Quicksort.
Merge Sort is a useful sort to know if you are doing External Sorting. The need for this will increase as data sizes increase. The traditional Merge Sort requires double space. To eliminate this issue, you are to implement Natural Merge using a linked implementation. In your analysis be sure to compare to the effect of using a straight Merge Sort instead.
Create input files of four sizes: 50, 1000, 2000, 5000 and 10000 integers. For each size file make 3 versions. On the first use a randomly ordered data set. On the second use the integers in reverse order. On the third use the
integers in normal ascending order. (You may use a random number generator to create the randomly ordered file, but it is important to limit the duplicates to <1%. Alternatively, you may write a shuffle function to randomize one of your ordered files.) This means you have an input set of 15 files plus whatever you deem necessary and reasonable. Files are available in the Blackboard shell, if you want to copy them. Your data should be formatted so that each number is on a separate line with no leading blanks. There should be no blank lines in the file. Even though you are limiting the occurrence of duplicates, your sorts must be able to handle duplicate data.
Each sort must be run against all the input files. With five sorts and 15 input sets, you will have 75 required runs.
The size 50 files are for the purpose of showing the sorting is correct. Your code needs to print out the comparisons and exchanges (see below) and the sorted values. You must submit the input and output files for all orders of size 50, for all sorts. There should be 15 output files here.
The larger sizes of input are used to demonstrate the asymptotic cost. To demonstrate the asymptotic cost you will need to count comparisons and exchanges for each sort. For these files at the end of each run you need to print the number of comparisons and the number of exchanges but not the sorted data. It is to your advantage to add larger files or additional random files to the input - perhaps with 15-20% duplicates. You may find it interesting to time the runs, but this should be in addition to counting comparisons and exchanges.
Turn in an analysis comparing the two sorts and their performance. Be sure to comment on the relative numbers of exchanges and comparison in the various runs, the effect of the order of the data, the effect of different size files, the effect of different partition sizes and pivot selection methods for Quicksort, and the effect of using a Natural Merge Sort. Which factor has the most effect on the efficiency? Be sure to consider both time and space efficiency. Be sure to justify your data structures. Your analysis must include a table of the comparisons and exchanges observed and a graph of the asymptotic costs that you observed compared to the theoretical cost. Be sure to justify your choice of iteration versus recursion. Consider how your code would have differed if you had made the other choice.
Answers
The necessary conditions and procedures needed to accomplish this assignment is given below. Quicksort is an algorithm used to sort data in a fast and efficient manner.
What is the Quicksort?Some rules to follow in the above work are:
A)Choose the initial element of the partition as the pivot.
b) Utilize the same method to select the pivot, but switch to insertion sort as the concluding step for partitions that contain 100 or fewer elements.
Lastly, Utilize the same method of pivot selection, but choose insertion sort for partitions that are of a size equal to or lesser than 50 in order to accomplish the task.
Learn more about Quicksort from
https://brainly.com/question/29981648
#SPJ1
Types of Selective Enforcement?
Answers
Answer:
In law, selective enforcement occurs when government officials (such as police officers, prosecutors, or regulators) exercise discretion, which is the power to choose whether or how to punish a person who has violated the law. The biased use of enforcement discretion, such as that based on racial prejudice or corruption, is usually considered a legal abuse and a threat to the rule of law.
In some cases, selective enforcement may be desirable.[1] For example, a verbal warning to a teenager may effectively alter their behavior without resorting to legal punishment and with the added benefit of reducing governmental legal costs. In other cases, selective enforcement may be inevitable. For example, it may be impractical for police officers to issue traffic tickets to every driver they observe exceeding the speed limit, so they may have no choice but to limit action to the most flagrant examples of reckless driving. Therefore, the mere fact that a law is selectively enforced against one person and not against another, absent bias or pattern of enforcement against a constitutionally-protected class, is not illegal.
1. find the network address for 172.22.49.252/17
2. find the last valid assignable host address on the network that host 172.22.4.129 with mask 255.255.255.192 is a part of
3.find the first and last address of the subnet containing 192.167.25.25/16
4.what is the broadcast address of 10.75.96.0/20?
Answers
Answer:
1. The network address for 172.22.49.252/17 is 172.22.0.0/17.
2. The last valid assignable host address of 172.22.4.129/26 is 172.22.4.190.
3. The first and last host address of 192.167.25.25/16 is 192.167.0.1 and 192.167.255.254.
4. The broadcast address of 10.75.96.0/20 is 10.75.111.255
Explanation:
Subnetting in networking is the process of managing the use of host addresses and subnet masks of a network IP address. For example, the IP address "172.22.49.252/17" is a class B address that receives an extra bit from the third octet which changes its subnet-mask from "255.255.0.0" to "255.255.128.0". with this, only 32766 IP addresses are used, with the network address of "172.22.0.0/17".
How To Approach Data Center And Server Room Installation?
Answers
Answer:
SEE BELOW AND GIVE ME BRAINLEST
Explanation:
Make a plan for your space: Determine how much space you will require and how it will be used. Consider power requirements, cooling requirements, and potential growth.
Choose your equipment: Based on your unique requirements, select the appropriate servers, storage devices, switches, routers, and other equipment.
Create your layout: Determine the room layout, including rack placement, cabling, and power distribution.
Set up your equipment: Install the servers, storage devices, switches, and other equipment as planned.
Connect your equipment: Connect and configure your servers and other network devices.
Check your systems: Check your equipment to ensure that everything is operating properly.
Maintain and monitor: To ensure maximum performance, always check your systems for problems and perform routine maintenance.
Our goal is to develop a very simple English grammar checker in the form of a boolean function, isGrammatical(wordList). To begin, we will define a sentence to be grammatical if it contains three words of form: determiner noun verb. Thus
[“the”, “sheep”, “run”] is grammatical but [“run”, “the”, “sheep”] is not grammatical nor is
[“sheep”, “run”]. By tagging convention, determiners are tagged as DT, nouns as NN, verbs as VB, and adjectives (which we discuss later) as JJ. The tagSentence function from the tagger module will help you convert your wordlist to tags; a challenge is that some words (such as swing) have multiple definitions and thus multiple parts of speech (as swing is a noun and swing is a verb). Carefully examine the results returned by tagSentence when defining the logic of isGrammatical.
Note that by our current definition, we are not concerned with other aspects of grammar such as agreement of word forms, thus “an sheep run” would be considered as grammatical for now. (We will revisit this concern later.)
[3 points]
Add the words “thief”, “crisis”, “foot”, and “calf” to the lexicon.txt file, and modify wordforms.py so that it generates their plural forms correctly (“thieves”, “crises”, “feet”, “calves”). In terms of categories for the lexicon.txt, thief is a person, crisis and feet are inanimates. Interestingly, ‘calf’ might be an animal (the young cow) but might be an inanimate (the part of the body).
We are not yet using plurals in our sentences, but you should be able to add additional tests within the wordforms.py file to validate that these new words and forms are handled properly.
[3 points]
The original lexicon includes singular nouns such as cat but not plural forms of those nouns such as cats, and thus a sentence such as “the cats run” is not yet deemed as grammatical. However, the wordforms module does include functionality for taking a singular noun and constructing its plural form.
Modify the code in tagger.py so that it recognizes plural forms of nouns and tags them with NNS. We recommend the following approach:
update the loadLexicon function as follows. Every time you encounter a word that is a noun from the original lexicon.txt file, in addition to appending the usual (word,label), add an extra entry that includes the plural form of that noun, as well as a label that adds an ‘s’ to the original label. For example, when encountering ‘cat’ you should not only add (‘cat’,’animal’) to the lexicon but also (‘cats’,’animals’).
Then update the the labelToTag function to return the new tag NNS when encountering one of those plural labels such as ‘animals’.
Test your new functionality on sentences such as “the cats run” as well as with your new plurals such as “thieves”.
[2 points]
The original lexicon includes verbs such as run but not 3rd person singular forms of those verbs that end in -s such as runs, and thus a sentence such as “the cat runs” is not yet deemed as grammatical. As you did with nouns in the previous step, modify the software so that 3rd person singular verbs are added to the lexicon and tagged as VBZ. Test this new functionality on sentences such as “the cat runs” and
“the sheep runs”.
[2 points]
Now we have both plural nouns and 3rd person singular verbs, however the grammar checker currently doesn’t match them and thus accepts sentences like
“the cat run” and “the cats runs”, neither of which is truly grammatical. Update the rules so that it requires the tag VBZ on the verb if the noun has the singular tag NN, and requires the tag VB on the verb if the noun has the plural tag NNS. Add some test cases to ensure the program is working as intended. Include tests with unusual forms such as the noun “sheep” that can be singular or plural; thus “the sheep runs” and “the sheep run” are grammatical. Make sure to update any previous tests to conform to these new expectations.
[2 points]
Update your grammar to allow any number of optional adjectives between the determiner and noun in a sentence, thereby allowing sentences such as
“the big sheep run” and “the big white sheep run”, though disallowing sentences such as “the cat sheep run”.
Answers
Using the knowledge in computational language in python it is possible to write a code that form of a boolean function, isGrammatical(wordList). To begin, we will define a sentence to be grammatical if it contains three words of form: determiner noun verb.
Writting the code:# importing the library
import language_tool_python
# creating the tool
my_tool = language_tool_python.LanguageTool('en-US')
# given text
my_text = 'A quick broun fox jumpps over a a little lazy dog.'
# correction
correct_text = my_tool.correct(my_text)
# printing some texts
print("Original Text:", my_text)
print("Text after correction:", correct_text)
See more about python at brainly.com/question/18502436
#SPJ1

______ is a software that criminal installs on a computer designed to steal
information, damage files or stop computer from working properly.
Answers
Answer: identity scrubber
Explanation:
Running Identity Scrubber will let you know where information such as credit card numbers, social security or driver license numbers, bank account information, passwords, telephone numbers, and any custom data.
What would game programmers do when decomposing a task in a modular program?
Answers
1. Identify the overall task or feature: Game programmers start by identifying the larger task or feature they want to implement, such as player movement, enemy AI, or collision detection.
2. Analyze the task: They analyze the task to understand its requirements, inputs, and desired outputs. This helps them determine the necessary functionality and behavior.
3. Identify subtasks or components: They identify the subtasks or components that make up the larger task. For example, in the case of player movement, this could involve input handling, character animation, physics simulation, and rendering.
4. Break down the subtasks further: Each subtask can be further decomposed into smaller, more specific functions or modules. For example, input handling might involve separate functions for keyboard input, mouse input, or touch input.
5. Define interfaces: They define clear interfaces between the modules, specifying how they interact and communicate with each other. This helps ensure modularity and maintainability of the code.
6. Implement and test modules: Game programmers then proceed to implement each module or function, focusing on their specific responsibilities. They can test and iterate on these smaller units of functionality independently.
7. Integrate and test the modules: Finally, they integrate the modules together, ensuring they work harmoniously and produce the desired outcome. Thorough testing is conducted to verify that the overall task or feature functions correctly.
By decomposing tasks in this manner, game programmers can effectively manage the complexity of game development, promote code reusability, enhance collaboration, and facilitate the maintenance and future expansion of the game.
When decomposing a task in a modular program, game programmers follow a structured approach to break down the task into smaller, more manageable components.
This process is crucial for code organization, maintainability, and reusability. Here's an outline of what game programmers typically do:
1. Identify the task: The programmer begins by understanding the task at hand, whether it's implementing a specific game feature, optimizing performance, or fixing a bug.
2. Break it down: The task is broken down into smaller subtasks or functions that can be handled independently. Each subtask focuses on a specific aspect of the overall goal.
3. Determine dependencies: The programmer analyzes the dependencies between different subtasks and identifies any order or logical flow required.
4. Design modules: Modules are created for each subtask, encapsulating related code and functionality. These modules should have well-defined interfaces and be independent of each other to ensure reusability.
5. Implement and test: The programmer then implements the modules by writing the necessary code and tests their functionality to ensure they work correctly.
6. Integrate modules: Once individual modules are tested and verified, they are integrated into the larger game program, ensuring that they work together seamlessly.
By decomposing tasks into modules, game programmers promote code organization, readability, and ease of maintenance. It also enables parallel development by allowing different team members to work on separate modules simultaneously, fostering efficient collaboration.
For more such questions on programmers,click on
https://brainly.com/question/30130277
#SPJ8
List the name and purpose of twenty (20) different C++ commands.
Answers
Answer:
Drivers and help a new program to run
Please help me I don’t know what I’m doing wrong.


Answers
Answer:
Explanation:
I noticed the \n, \n will cause the new line break, delete it.
try code below:
System.out.println(" " + " " + "NO PARKING");
System.out.println("2:00 - 6:00 a.m.");
In Coral Code Language - A half-life is the amount of time it takes for a substance or entity to fall to half its original value. Caffeine has a half-life of about 6 hours in humans. Given the caffeine amount (in mg) as input, output the caffeine level after 6, 12, and 18 hours.
Ex: If the input is 100, the output is:
After 6 hours: 50.0 mg
After 12 hours: 25.0 mg
After 18 hours: 12.5 mg
Note: A cup of coffee has about 100 mg. A soda has about 40 mg. An "energy" drink (a misnomer) has between 100 mg and 200 mg.
Answers
To calculate the caffeine level after 6, 12, and 18 hours using the half-life of 6 hours, you can use the formula:
Caffeine level = Initial caffeine amount * (0.5 ^ (time elapsed / half-life))
Here's the Coral Code to calculate the caffeine level:
function calculateCaffeineLevel(initialCaffeineAmount) {
const halfLife = 6; // Half-life of caffeine in hours
const levelAfter6Hours = initialCaffeineAmount * Math.pow(0.5, 6 / halfLife);
const levelAfter12Hours = initialCaffeineAmount * Math.pow(0.5, 12 / halfLife);
const levelAfter18Hours = initialCaffeineAmount * Math.pow(0.5, 18/ halfLife);
return {
'After 6 hours': levelAfter6Hours.toFixed(1),
'After 12 hours': levelAfter12Hours.toFixed(1),
'After 18 hours': levelAfter18Hours.toFixed(1)
};
}
// Example usage:
const initialCaffeineAmount = 100;
const caffeineLevels = calculateCaffeineLevel(initialCaffeineAmount);
console.log('After 6 hours:', caffeineLevels['After 6 hours'], 'mg');
console.log('After 12 hours:', caffeineLevels['After 12 hours'], 'mg');
console.log('After 18 hours:', caffeineLevels['After 18 hours'], 'mg');
When you run this code with an initial caffeine amount of 100 mg, it will output the caffeine levels after 6, 12, and 18 hours:
After 6 hours: 50.0 mg
After 12 hours: 25.0 mg
After 18 hours: 12.5 mg
You can replace the initialCaffeineAmount variable with any other value to calculate the caffeine levels for different initial amounts.
for similar questions on Coral Code Language.
https://brainly.com/question/31161819
#SPJ8
Read string integer value pairs from input until "Done" is read. For each string read, if the following integer read is less than or equal to 45, output the string followed by ": reorder soon". End each output with a newline.
Ex: If the input is Tumbler 49 Mug 7 Cooker 5 Done, then the output is:
Mug: reorder soon
Cooker: reorder soon
Answers
The program to Read string integer value pairs from input until "Done" is read. For each string read, if the following integer read is less than or equal to 45, output the string followed by ": reorder soon" is given below.
Here's a Python program solution to your problem for given input:
while True:
# Read string integer pairs from input
try:
name = input()
if name == "Done":
break
value = int(input())
except ValueError:
print("Invalid input format")
continue
# Check if the value is less than or equal to 45
if value <= 45:
print(name + ": reorder soon")
Thus, this program reads string integer pairs from input until "Done" is read. For each pair, it checks if the integer value is less than or equal to 45.
For more details regarding programming, visit:
https://brainly.com/question/11023419
#SPJ1
5.3.8 higher/lower 2.0
Answers
The code that configures Higher /Lower (Guessing Game) is
secret_number = 3.3312
while True:
guess = float(input("Enter a guess: "))
if round(guess, 2) == round(secret_number, 2):
print "Correct!"
break
elif (guess > secret_number):
print "Too high!"
else:
print "Too low!"
How does the above code work?The Python code implements a guessing game where users enter their guesses.
It compares the guesses to a secret number and provides feedback if the guess is too high or too low. The game continues until the correct guess is made, displaying "Correct!" as the output.
Learn more about code at:
https://brainly.com/question/26134656
#SPJ1
Which devices are most likely to communicate with the internet? Select 3 options.
A. iron
B. calculator
C. smart TV
D. printer
E. cash register
Answers
Answer:smart TV, printer, and cash register
Explanation:Just put it
Answer:
- smart TV
- printer
- cash register
Explanation:
All of these devices are capable of operating digitally, and can be used to communicate with the internet.
I hope this helped!
Good luck <3