Which of the following tests can be used to assess whether variances are equal between multiple groups? Welch's test Shapiro-Wilk test Goodness of Fit test Levene test 26 10 points Cancer patients were treated with a new cell-based therapeutic to aid in reducing tumor size. The data table below shows the patients' adverse reactions to this treatment: Weak reaction Strong reaction Male patients Medium reaction 203 110 213 138 182 Female patients 154 Is the sex (male or female) of the patient linked to the severity of the adverse reaction that is observed? Show your work and explain your logic below. Bold or circle your final answer. 0000 The correlation coefficient (r) is used for linear, exponential, and logarithmic relationships. True False
Answers
The test that can be used to assess whether variances are equal between multiple groups is the Levene test.
The Levene test is a hypothesis test for the equality of variances in a statistical population. It is named after the American statistician Howard Levene. It is commonly used to check the null hypothesis of homoscedasticity or equal variances across k groups. The test is used to determine if two or more groups have different variances or if the variance is unequal. The null hypothesis of the Levene test is that the variance of the populations from which the groups are drawn is equal. The Levene test is an alternative to the F-test for equal variances. Therefore, it can be concluded that the Levene test can be used to assess whether variances are equal between multiple groups.
Know more about Levene test here:
https://brainly.com/question/28584328
#SPJ11
Related Questions
The inverse of the logarithmic function f(x) = log0. 5x is f−1(x) = 0. 5x. What values of a, b, and c complete the table for the inverse function?.
Answers
The values of a, b, and c to complete the table for the inverse of the logarithmic function is 2,1 and -2 respectively.
What is the inverse of the logarithmic function?The Inverse of the logarithmic function is an exponential function.
The given logarithmic function is,
\(f(x) = \log_{0. 5}x\)
The inverse of the given logarithmic function is,
\(f^{-1}(x) = 0.5^x.\)
Put the value of x as -1 from the table attached below, to find the value of a.
\(f^{-1}(-1) = 0.5^{(-1)}\\f^{-1}(-1) = 2\)
Similarly, put the value of x as 0 from the table attached below, to find the value of b.
\(f^{-1}(0) = 0.5^{(0)}\\f^{-1}(0) = 1\)
Now, put the value of x as 2 from the table attached below, to find the value of c.
\(f^{-1}(2) = 0.5^{(2)}\\f^{-1}(2) = -2\)
Thus, the values of a, b, and c to complete the table for the inverse of the logarithmic function is 2,1 and -2 respectively.
Learn more about the inverse of the logarithmic function here;
https://brainly.com/question/12082934

Solve for how many employees did the company have a year ago?

Answers
Answer
35000
Explanation
\(\begin{gathered} \frac{x}{1}=\frac{48000}{1.38} \\ x=35000 \end{gathered}\)please tell me please

Answers
Answer:
B = 40
C = 65
Step-by-step explanation:
marking as brainliest + 80 pts <3 do it all please and if you have any questions you can ask here or add my dxisxcord, insxtax or snxapcxhxat so i can send the image up close if you can't see, js ask for it :P

Answers
Answer: BRAINLIEST?
PART 1
In january she recives the discount but not in Febuary
25*12= 300 For Jan
59.99*10= 599.90 For Feb
Total: 899.90 dollars
PART 2
x stands for amount of months
59.99x=359.94
Divide both sides by 59.99
x= 6
Step-by-step explanation:
Answer:
hi i know she alreaady andwerd but hi
Step-by-step explanation:
If wy is the midsegment of triangle QRS. Find the value of x, if WY=80 and RS=2x+20
Answers
If wy is the midsegment of triangle QRS. Then the value of x, if WY=80 and RS=2x+20 is calculated to be 70.
In a triangle, the midsegment connecting the midpoints of two sides is equal to the half the length of the third side. Therefore, we have:
WY = 0.5 x RS
Substituting the given values, we will be getting,
80 = 0.5 x (2x+20)
Simplifying this equation, we get:
80 = x + 10
Subtracting 10 from both sides, we get:
x = 70
Therefore, from the calculations above, it can be concluded that the value of x is found oout to be 70.
Learn more about triangle :
https://brainly.com/question/21036800
#SPJ4
2. how many license plates can by made using either three uppercase english letters followed by three digits or four uppercase english letters followed by two digits?
Answers
There would be 63,273,600 and 43,524,000 license plates, if repetition is allowed, and not, respectively that can be made using either three uppercase English letters followed by three digits or four uppercase English letters followed by two digits.
Based on the given information, a license plate may either be:
1. three uppercase English letters followed by three digits
26 ways to fill in the first, second, and third letter and
10 ways to fill in the first, second, and third digit
2. four uppercase English letters followed by two digits
26 ways to fill in the first, second, third, and fourth letter and
10 ways to fill in the first and second digit
Thus, by Fundamental Principle of Counting, there are 63,273,600 possible license plates, if repetition is allowed, and 43,524,000 possible license plates, if repetition is not allowed.
(with repetition)
1. 26 x 26 x 26 x 10 x 10 x 10 = 17,576,000
2. 26 x 26 x 26 x 26 x 10 x 10 = 45,697,600
17,576,000 + 45,697,600 = 63,273,600
(without repetition)
1. 26 x 25 x 24 x 10 x 9 x 8 = 11,232,000
2. 26 x 25 x 24 x 23 x 10 x 9 = 32,292,000
11,232,000 + 32,292,000 = 43,524,000
Learn more about counting principle here: brainly.com/question/16050707
#SPJ4
Write a logical statement defining the relation (⊂) in terms of (∈). 14. Let A and B be sets. Prove that (A−B)∩(B−A)=∅.
Answers
The logical statement that defines the relation (⊂) in terms of (∈) is:
A ⊂ B if every element of A is an element of B.
To prove that (A-B) ∩ (B-A) = ∅,
follow the steps below:
Step 1: To begin, assume that x ∈ (A-B) ∩ (B-A)
Step 2: This means that x is an element of both A-B and B-A.
Step 3: Since x ∈ A-B, x ∈ A, but x ∉ B.
Step 4: Since x ∈ B-A, x ∈ B, but x ∉ A.
Step 5: Since x ∈ A and x ∉ B, it is impossible for x to be in both A and B.
Step 6: Therefore, x cannot be in (A-B) ∩ (B-A).
Step 7: This means that (A-B) ∩ (B-A) is an empty set, or ∅.
Step 8: Thus, (A-B) ∩ (B-A) = ∅.
To know more about relation visit:
https://brainly.com/question/2253924
#SPJ11
PLEASE HELP
WILL GIVE BRAINLIEST AND 5.0 STAR RATING
Answers
Answer:
I can't find the question
BRAINLIEST ANSWER!! I need help ASAP!

Answers
Answer:
n = -9.5
Step-by-step explanation:
6n + 15 = -42
6n = -57
n = -9.5
Find y.
Round to the nearest tenth:
31°
y
X
400 ft
y = [? ]ft
![Find y.Round to the nearest tenth:31yX400 fty = [? ]ft](https://i5t5.c14.e2-1.dev/h-images-qa/contents/attachments/dAOwZ5551CCyAzV1NN84bFZ42Y2StDWu.png)
Answers
Answer:
y = 240.3 ft
Step-by-step explanation:
Use trigonometric ratio to find y:
Thus,
Reference angle = 90° - 31° = 59°
Opposite = 400 ft
Adjacent = y
Therefore:
Tan 59° = 400/y
Multiply both sides by y
y*tan 59 = 400
Divide both sides by tan 59
y = 400/tan 59
y = 240.3 ft (to the nearest tenth)
Describe the translation of the point to its image. (-2,-3) to (-2,4)
Answers
Up 8 Units, Hope this helps :)
You have just spoken to your insurance agent and you are interested in investing in a Whole Life insurance policy
Given that you are a 26-year-old healthy female, determine the annual premium for a policy with a face value of
$76,429. Use the table provided below and round your answer to the nearest cent where necessary
Permanent Insurance
Age Whole Life
20-Payment 20-Year
Life
Endowment
Male Female Male Female Male Female
25 $16.38 $14.38 $28.40 $25.04 $37.02 $34.87
26 16.91 14.77 29.11 25.96 37.67 35.30
27 17.27 15.23 29.97 26.83 38.23 35.96
28 17.76 15.66 30.68 27.54 38.96 36.44
a $1,164.01
C. $1,128.86
b. $1,099.05
d. $1,292 41
Answers
Based on the table provided, the annual premium for a Whole Life insurance policy with a face value of $76,429 for a healthy 26-year-old female would be $1,099.05 (option b).
To determine the annual premium for a 26-year-old healthy female interested in a Whole Life insurance policy with a face value of $76,429, follow these steps:
1. Locate the correct age and gender in the provided table: For a 26-year-old female, the Whole Life premium rate is $14.77 per $1,000 of face value.
2. Calculate the premium based on the face value: Divide the face value by 1,000 ($76,429 / 1,000 = 76.429).
3. Multiply the premium rate by the result from step 2: ($14.77 * 76.429 = $1,128.86233).
4. Round the result to the nearest cent: $1,128.86.
So, the annual premium for the Whole Life insurance policy for a 26-year-old healthy female with a face value of $76,429 is $1,128.86 (Option C).
Learn more about Multiply at: brainly.com/question/23536361
#SPJ11
Your friend loans you $20,000 for school. In five years he wants
$40,000 back. What is the interest rate he is charging you?
Remember to show your work.
Answers
The interest rate your friend is charging you for the $20,000 loan is 20% per year.
What is the interest rate on the loan?
The simple interest is expressed as;
A = P( 1 + rt )
Where A is accrued amount, P is principal, r is the interest rate and t is time.
Given that;
The Principal P = $20,000
Accrued amount A = $40,000
Elapsed time t = 5 years
Interest rate r =?
Plug these values into the above formula and solve for the interest rate r:
\(A = P( 1 + rt )\\\\r = \frac{1}{t}( \frac{A}{P} -1 ) \\\\r = \frac{1}{5}( \frac{40000}{20000} -1 ) \\\\r = \frac{1}{5}( 2 -1 ) \\\\r = \frac{1}{5}\\\\r = 0.2 \\\\\)
Converting r decimal to R a percentage
Rate R = 0.2 × 100%
Rate r = 20% per year
Therefore, the interest rate is 20% per year.
Learn more about simple interest here: brainly.com/question/25845758
#SPJ1
the height of adult women in france is a normally distributed random variable with a mean of 64 inches and a standard deviation of 2.4 inches. find the probability that a randomly chosen women is less than 62 inches tall.
Answers
The probability that a randomly selected woman is less than 62 inches tall is approximately 20.23%.
To solve this problem, we need to standardize the height value of 62 inches using the mean and standard deviation given.
Allow X be the height of adult women in France. Then we've got:
X ~ N(64, 2.4)
To discover the probability that a randomly chosen woman is less than 62 inches tall, we need to discover P(X < 62).
Using the standard regular distribution components, we can standardize X as follows:
Z = (X - μ) / σ
Where μ is the imply and σ is the standard deviation of the regular distribution, and Z is a general regular random variable.
Substituting the given values, we get:
Z = (62 - 64) / 2.4 = -0.8333 (approx)
Now, we want to discover the chance P(Z < -0.8333) using the standard normal distribution table or a calculator.
Using a standard normal distribution table, we discover that
P(Z < -0.8333) is approximately 0.2023.
Therefore, the probability that a randomly selected woman is less than 62 inches tall is approximately 0.2023 or 20.23%.
Learn more about Standard Deviation:-
https://brainly.com/question/475676
#SPJ4
A data set consists of a list of eye colors from 250 randomly selected statistics students. which measure of center appears to be best?
graphs
mode
nonzero axis
relative frequency
Answers
The best measure of center for the given data set of eye colors from 250 randomly selected statistics students would likely be the mode, representing the most frequently occurring eye color.
To determine which measure of center would be best for the given data set, which consists of a list of eye colors from 250 randomly selected statistics students, we can consider the following options:
Mode: The mode represents the most frequently occurring eye color in the data set. If there is a clear eye color that occurs more frequently than others, the mode can be a suitable measure of center. For example, if the majority of students have brown eyes, and brown is the most common eye color in the data set, then the mode would be a relevant measure of center.
Nonzero axis: It is unclear what is meant by "nonzero axis" in this context. Please provide additional clarification if this term refers to a specific statistical measure.
Relative frequency: Relative frequency refers to the proportion or percentage of observations that fall into each category. In this case, it would involve calculating the relative frequency of each eye color category based on the 250 students. This measure of center can provide a sense of the distribution of eye colors among the students and identify any dominant categories.
Graphs: Graphical representations, such as bar charts or pie charts, can visually display the distribution of eye colors among the 250 students. These graphs can help identify any prominent eye color categories and provide a visual summary of the data.
Ultimately, the best measure of center for the data set would depend on the distribution of eye colors and whether there is a clear dominant category. It is advisable to explore all the mentioned options (mode, relative frequency, and graphs) to gain a comprehensive understanding of the data and determine the most appropriate measure of center.
To know more about data set, visit:
https://brainly.com/question/32936043
#SPJ11
(ch8) suppose a 95% confidence interval has been constructed when the sample size is n. now, we increase the sample size 4n. other things being equal, the width of this new confidence interval will be .
Answers
About 50 percent of its former width.
Now, According to the question:
Let's assume that our parameter of interest is given by θ and in order to construct a confidence interval we can use the following formula:
θ = ± ME(θ vector)
Where θ vector is an estimator for the parameter of interest and the margin of error is defined usually if the distribution for the parameter is normal as:
ME = \(z_\alpha\)SE
Where \(z_\alpha /2\) is a quantile from the normal standard distribution that accumulates \(\alpha /2\) of the area on each tail of the distribution. And SE represent the standard error for the parameter.
If our parameter of interest is the population proportion the standard of error is given by:
SE =\(\frac{p(1-p)}{n}\)
And if our parameter of interest is the sample mean the standard error is given by:
SE = \(\frac{1}{\sqrt{n} }\)
As we can see the standard error for both cases assuming that the other things remain the same are function of n the sample size and we can write this as:
SE = f(n)
And since the margin of error is a multiple of the standard error we have that
ME = f(n)
Now if we find the width for a confidence interval we got this:
Width = θ + ME (θ) - [θ - ME (θ)]
Width = 2ME(θ)
And we can express this as:
Width = 2f(n)
And we can define the function f(n) = \(\frac{1}{\sqrt{n} }\) since as we can see the margin of error and the standard error are function of the inverse square root of n. So then we have this:
\(Width_i\) = \(2\frac{1}{\sqrt{n} }\)
The subscript i is in order to say that is with the sample size n
If we increase the sample size from n to 4n now our width is:
\(Width_f\) = \(2\frac{1}{\sqrt{4n} }\) = \(2\frac{1}{\sqrt{n}\sqrt{4} }\) = \(\frac{1}{\sqrt{n} }\) = 1/2 \(Width_i\)
The subscript f is in order to say that is the width for the sample size 4n.
So then as we can see the width for the sample size of 4n is the half of the with for the width obtained with the sample size of n. So then the best option for this case is:
about 50 percent of its former width.
Learn more about Sample Size at:
https://brainly.com/question/25894237
#SPJ4
This is incomplete question:
Complete question is this :
In constructing a 95 percent confidence interval, if you increase n to 4n, the width of your confidence interval will (assuming other things remain the same) be:
about 25 percent of its former width.
about two times wider.
about 50 percent of its former width.
about four times wider.
Which exponential equation is equivalent to the logarithmic equation below?log 784 = aA.10a = 784B.78410 = aC.784a = 10D.a10 = 784

Answers
Given the Logarithmic Expression:
\(log784=a\)You need to remember that, by definition, a Logarithmic Expression that has this form:
\(log_bm=n\)can be rewritten in this Exponential Form:
\(b^n=m\)In this case, you can identify that the logarithm has base 10.
Then, you know that:
\(\begin{gathered} b=10 \\ m=784 \\ n=a \end{gathered}\)Therefore, you can rewrite the expression in this form:
\(10^a=784\)Hence, the answer is: Option A.
a coin is tossed and a die is rolled. find the probability of getting a head and a number greater than 5
Answers
The probability of getting a head and a number greater than 5 i.e, independent events is 0.0833.
A coin is tossed and a die is rolled. These are two independent events. Two events are defined as independent if the outcome of one event has no effect on the outcome of another event. The probability is calculated by multiplying two independent probabilities together, i.e, P(A and B) = P(A) x P(B)
We have, Let us assume two independent events be ,
A : A coin is tossed and the head is thrown.
B : A die is rolled, and a number greater than 5 occurs.
Total possible outcomes when a coin tossed = 2 ={ H ,T }
Total possible outcomes when a die rolled = 6 = { 1,2,3,4,5,6} .
We have to determine probability of getting a head and a number greater
than 5.
Probability of getting the head on toss a coin, P(A) = 1/2
Probability of occuring a number greater than 5 on rolling a die = P(B) = 1/6
So, the probability of getting a head on coin and a number greater than 5 on die =P(A)×P(B)
=(1/2)× 1/6 = 1/12=0.0833
Hence, required probability is 0.0833.
To learn more about probability, visit:
https://brainly.com/question/13604758
#SPJ4
Which pairs of rectangles are similar polygons?
Select each correct answer.
(See image for details.)

Answers
The pairs of rectangles are similar polygons; Option C and Option D.
What is a polygon?A polygon is a closed figure made up of three or more line segments connected end to end.
Similar polygon beings their sides have equivalent ratios to each other.
Two polygons whose corresponding angles are congruent and the lengths of the corresponding sides are proportional.
C. 1.89/2.1 = 81/0.9 = 90
D. 120 / 24 = 60 / 12 = 5
Hence, Option C and Option D are similar polygons only.
Learn more about polygon here;
https://brainly.com/question/14422754
#SPJ1
Please help! I will mark as brainliest IF answer is right. <3

Answers
Step-by-step explanation:
\( - 1 \: is \: the \: answer\)

Solution is in attachment !
Quotient :
\(6 {p}^{3} + 10 {p}^{2} + 5p + 2\)Remainder :
\( - 1\)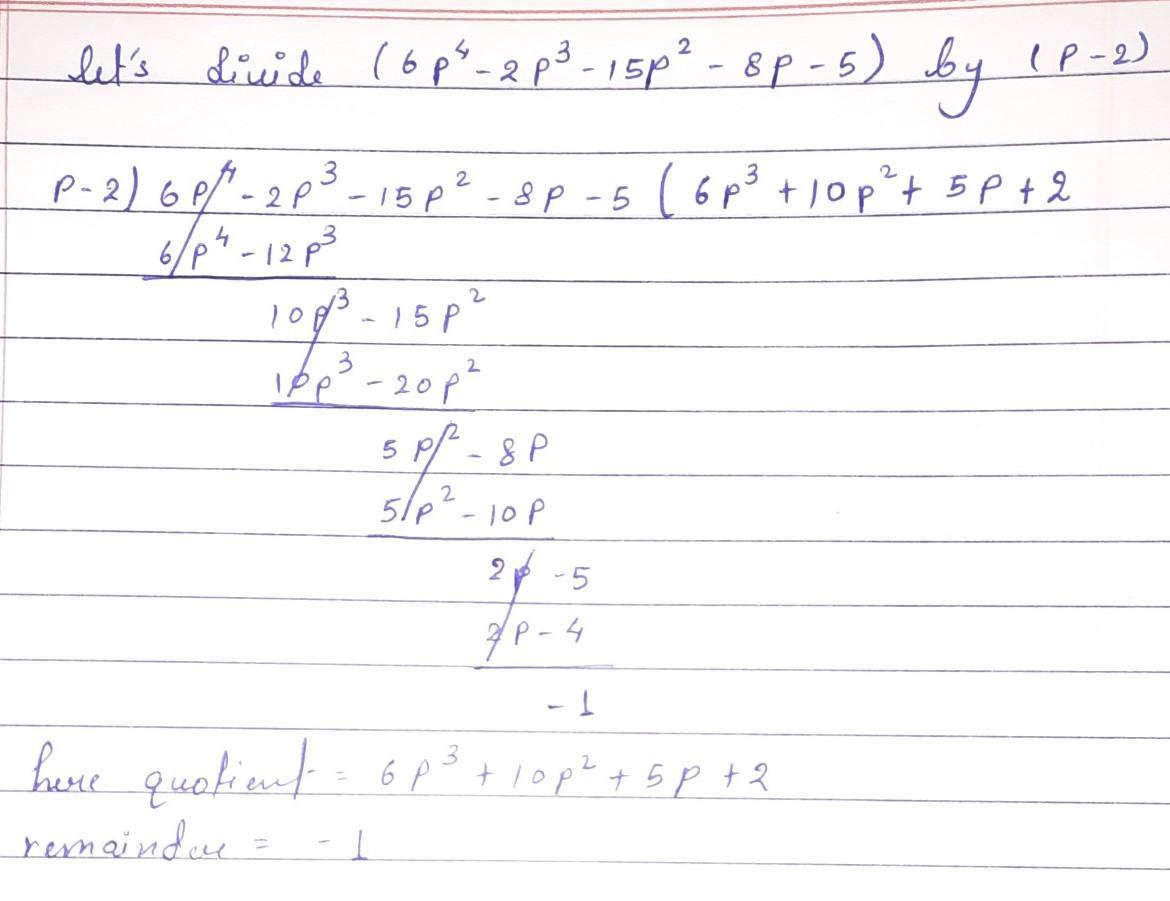
What’s the value of |4|
Answers
Answer:
The value is 4
Step-by-step explanation:
This is because the value of an absolute number is always positive so the absolute value of 4 would remain 4.
Answer: 4
Step-by-step explanation: The absolute value is how far a number is away from 0
how many cubic millimeters are in a cubic centimeter?
Answers
1000 cubic millimeters are in a cubic centimeter.
'What is cubic centimeter?'
There are 1000 cubic millimeters in one cubic centimeter (cm³) (mm³). Add 1000 to the cubic cm number to convert it to cubic mm.
For instance, multiplying 10 by 1000 results in 10000 mm3, or how many cubic mm there are in 10 cubic cm.
The volume of small items is measured in cubic centimeters, a tiny unit of measurement. Discover standard units of measurement, the definition of cubic centimeters, how to convert them, and how to measure volume using cubic centimeters. A little cube with sides that are 1 cm long occupies the same amount of space as a cubic centimeter.
know more about standard units here
https://brainly.com/question/29439077#
#SPJ4
eliminating design confounds from a study can... select one or more: a. lower the amount of systematic variance in a study b. make it more difficult to recruit participants c. make it easier to determine if the iv influences the dv d. make random assignment optional.
Answers
Eliminating design confounds from a study can make it easier to determine if the iv influences the dv
Option (c) is correct answer.
Confounding variables are a type of irrelevant variable that are related to a study’s independent and dependent variables. Thus failing to account for confounding variables can cause wrong estimation of the relationship between independent and dependent variables.
Random assignment of study subjects to exposure of any links between exposure and confounders which reduces potential for confounding by generating groups that are fairly comparable with respect to known and unknown confounding variables.
Eliminating designs confounds from a study facilitates estimating the relationship between independent variables and dependent variables and also randomly assigning subjects helps to eliminate confounding variables.
Hence the correct options is (c).
To know more about confounding variables here
https://brainly.com/question/29925460
#SPJ4
If curtis can carve 1/6 blocks of wood and he has 18 of them how many wooden blocks would have
Answers
Curtis would have carved 54 wooden blocks in total.
If Curtis can carve 1/6 block of wood and he has 18 of them.
We can find the total number of wooden blocks he would have carved as follows:
We can find out how many blocks of wood Curtis carves in one go by multiplying the fraction 1/6 by the total number of wooden blocks he has:
1/6 x 18 = 3 blocks
Therefore, Curtis can carve 3 wooden blocks.
However, this only tells us how many wooden blocks Curtis can carve in one go. If we want to find out how many wooden blocks he has carved in total, we need to multiply this number by the number of times he has carved.
So if he has carved 3 blocks of wood in one go and has done this 18 times, we can find the total number of wooden blocks he has carved by multiplying these two numbers.
3 blocks x 18 times = 54 wooden blocks
Therefore, Curtis would have carved 54 wooden blocks in total.
To learn more about fraction here:
https://brainly.com/question/17220365
#SPJ11
Decide!!!!!!!!!!!!!!!!!!!

Answers
Answer:
n = {9, 10}Step-by-step explanation:
Let the equation be:
n² - 19n + 91 = k²Multiply both sides by 4 and complete the square:
4n² - 76n + 364 = 4k²(2n)² - 2(2n)(19) + 19² + 3 = 4k²(2n - 19)² - 4k² = - 3(2n + 2k - 19)(2n - 2k - 19) = -3Since -3 = 1(-3) = (-1)*3, we have following options:
1)
2n + 2k - 19 = 12n - 2k - 19 = -3Eliminate k by adding up equations:
4n - 38 = -24n = 36n = 92)
2n + 2k - 19 = -12n - 2k - 19 = 3Eliminate k by adding up equations:
4n - 38 = 24n = 40n = 10Suppose a 5 × 8 coefficient matrix for a system has five pivot columns. Is the system consistent? Why or why not? Choose the correct answer below A. There is a pivot position in each row of the coefficient matrix The augmented matrix will have nine columns and will not have a row of O B. There is at least one row of the coefficient matrix that does not have a pivot position. This means the augmented matrix, which will have O C. There is a pivot position in each row of the coefficient matrix. The augmented matrix vill have six columns and will not have a row of the ○ D. *There is at least one row of the coefficient matrix that does not have a pivot position. This means the augmented matrix, which wil have the form 0 000 0 o 0 0so the system is consistent. nine columns, could have a row of the form 0 0 o o o 0 0 0 1so the system could be inconsistent. form 0 0 0 0 0 1 so the system is consistent. nine columns, must have a row of the form 0 0 0 0 0 00 0 1 so the system is inconsistent
Answers
D). There is at least one row of the coefficient matrix that does not have a pivot position. is the correct option. Since there is at least one row of the coefficient matrix that does not have a pivot position, the system is consistent.
This means the augmented matrix, which will have the form 0 000 0 o 0 0so the system is consistent. nine columns, could have a row of the form 0 0 o o o 0 0 0 1so the system could be inconsistent.What is a consistent system?A consistent system of equations has at least one solution. This means that the system is solvable, and there is a unique solution, no solution, or infinitely many solutions.
However, for a system of linear equations to be consistent, the rank of the coefficient matrix should be equal to the rank of the augmented matrix.What is a pivot position?A pivot position is a position in the coefficient matrix in a system of equations that contains the leading coefficient (the first non-zero entry in a row). These pivot positions indicate that a row has a leading coefficient, which means that the row is a pivot row and is used to solve a system of equations.
To know more about coefficient matrix visit:
https://brainly.com/question/31977726
#SPJ11
What is 22.5 rounded to the nearest tenth?
Answers
Answer:
20
Step-by-step explanation:
Answer:
23
Step-by-step explanation:
Have a great day :D
the sum of two numbers is 45. the greater number is 9 more than the other number. Find each number. use a system of linear equations to justify your answer
Answers
Answer:
18 and 27
Step-by-step explanation:
Let x = first (smaller) number
Let y = second (larger) number
Sum of two numbers is 45:
⇒ x + y = 45
The greater number is 9 more than the other number:
⇒ y = x + 9
Substitute y = x + 9 into x + y = 45 and solve for x:
⇒ x + (x + 9) = 45
⇒ 2x + 9 = 45
⇒ 2x = 36
⇒ x = 18
Substitute found value for x into y = x + 9 and solve for y:
⇒ y = 18 + 9
⇒ y = 27
Therefore, the two numbers are 18 and 27
Solution:
Let x and y be the numbers that sum up to 45.
Note that:
x + y = 45y + 9 = xSimplify the second equation such that the constant is the subject.
y + 9 = x=> -x + y = -9Use system of equations to solve for both variables.
x + y = 45-x + y = -9
=> 2y = 36=> y = 18Substitute the value of y into the second equation to find x.
y + 9 = x=> 18 + 9 = x=> 27 = xThe value of x and y is 27 and 18 respectively.
if the probability of a type i error (α) is 0.05, then the probability of a type ii error (β) must bea. 0.05b. 0.025c. 0.05d. none of these alternatives is correct
Answers
None of these alternatives is correct. The probability of a type ii error (β) is not directly determined by the probability of a type i error (α).
Type i and type ii errors are two types of errors that can occur in hypothesis testing. Type i error occurs when we reject a true null hypothesis, while type ii error occurs when we fail to reject a false null hypothesis.
The probability of a type i error (α) is typically set by the researcher or the significance level chosen for the test. A common value for α is 0.05, which means that there is a 5% chance of rejecting a true null hypothesis. However, the probability of a type ii error (β) depends on various factors such as the sample size, effect size, and the level of significance chosen for the test.
In general, the probability of a type ii error (β) decreases as the sample size increases or as the effect size increases. It also decreases if the level of significance chosen for the test is reduced. However, it is important to note that there is always a trade-off between type i and type ii errors. As the probability of type i error decreases, the probability of type ii error increases, and vice versa.
In conclusion, the probability of a type ii error (β) cannot be determined solely based on the probability of a type i error (α). It depends on several factors and should be considered along with the probability of type i error when making decisions about hypothesis testing.
Learn more about errors here:
https://brainly.com/question/30925212
#SPJ11
Brian is participating in a 4-day cross-country biking challenge. He biked for 48, 55, and 58 miles on the first three days. How many miles does he need to bike on the last day so that his average (mean) is 54 miles per day?
Answers
Answer:
55
Step-by-step explanation:
(55+55+58+48) ÷4
❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤