Calculate the lenght of the shadow cast on level groundby a radio mast 90m high when the elevationof the sun is 40degree
Answers
The length of the shadow cast on level ground by a radio mast 90m high when the elevation of the sun is 40 degrees is approximately 85.3 meters.
To calculate the length of the shadow, we need to use trigonometry. We can imagine a right-angled triangle, where the height of the mast is the opposite side, the length of the shadow is the adjacent side, and the angle of elevation is 40 degrees.
Using the trigonometric function tangent (tan), we can find the length of the shadow, which is equal to the opposite side (90m) divided by the tangent of the angle of elevation (40 degrees). Therefore, the length of the shadow is approximately 85.3 meters.
For more questions like Triangle click the link below:
https://brainly.com/question/2773823
#SPJ11
Related Questions
Suppose that A is an n x n diagonal matrix with rank r, where rsn. Which of the following is true about
A?
A. O is an eigenvalue with algebraic muitiplicity n-r
B. O is an eigenvalue, but there is not enough information to determine the geometric multiplicity
C O is an eigenvalue with geometric multiplicity ner
DO is not an eigenvalue.
Answers
A is an n x n diagonal matrix with rank r , where rsn and the statement (a)"O is an eigenvalue with algebraic muitiplicity n-r " about A is true
Since A is an n x n diagonal matrix with rank r, the number of non-zero entries on the diagonal is r. This means that there are n - r zero entries on the diagonal.
For any diagonal matrix, the eigenvalues are simply the entries on the diagonal. Since there are n - r zero entries, the eigenvalue O has a geometric multiplicity of n - r.
Therefore, the correct statement is that O is an eigenvalue with geometric multiplicity n - r.
To know more about eigenvalue refer here:
https://brainly.com/question/14415841
#SPJ11
for an independent-measures t statistic, what is the effect of increasing the number of scores in the samples?
Answers
Increasing the number of scores in the samples for an independent-measures t-statistic has the effect of increasing the likelihood of rejecting the null hypothesis while having little or no effect on measures of effect size.
As the sample-size increases, the t-statistic becomes more robust and accurate, which leads to a more precise estimate of the population parameter. This increased precision reduces the variability in t-statistic, which makes it easier to detect small differences between the means of the independent groups.
With a larger sample size, the t-statistic's sampling distribution approaches a normal-distribution, allowing for more reliable statistical inference. This results in a narrower confidence interval and a smaller p-value, increasing the likelihood of rejecting the null hypothesis when there is a true difference between the groups.
Therefore, increasing number of scores in samples enhances power of independent-measures t-statistic.
Learn more about T-Statistic here
https://brainly.com/question/19583193
#SPJ4
Got a math quiz happening, please help give a detailed explanation and I will give brainliest!

Answers
Answer:
-1.1
Step-by-step explanation:
3.1 - 1.3 = t + 2.9
t = 3.1 - 1.3 - 2.9
t = -1.1
Answer:
t = -1.1
Step-by-step explanation:
\(3.1 - 1.3 = t + 2.9 \\ 1.8 = t + 2.9 \\ 1.8 - 2.9 = t \\ - 1.1 = t \)
.) Mario has of a pineapple pizza in his refrigerater Mario orders 2 more pineapple pizzas from his local pizzeria. If he eats 1-3/6 of his pizzas for lunch, how much pizza does he have left?
Answers
Answer:
1/3 of pizza does mario have
Please help, I don't quite understand. I'm offering 30 points with Brainliest answer!

Answers
Answer:
-4
Step-by-step explanation:
a1 is 2
a2 = a1^2-5 = 4-5 = -1
a3 is a2^2-5 = 1-5 = -4
A pilot flew a jet from City A to City B, a distance of 2000 mi. On the return trip, the average speed was 20% faster than the outbound speed. The round-trip took 6 h 40 min. What was the speed from City A to City B
Answers
The speed from City A to City B is 275 mph.
To find the speed of the jet from City A to City B, we can use the concept of average speed and the given information about the round-trip duration.
Let's assume the outbound speed of the jet is x mph.
Since the return trip is 20% faster, the speed for the return trip would be 1.2x mph.
The total distance for the round-trip is 2000 miles, so the one-way distance is 1000 miles.
Now, let's calculate the time taken for each leg of the trip:
Outbound trip time = Distance / Speed = 1000 / x hours
Return trip time = Distance / Speed = 1000 / (1.2x) hours
According to the given information, the total round-trip duration is 6 hours and 40 minutes, which is equivalent to (6 + 40/60) hours = 6.67 hours.
Using the above information, we can set up an equation:
Outbound trip time + Return trip time = Total round-trip time
1000 / x + 1000 / (1.2x) = 6.67
To simplify the equation, we can multiply through by 1.2x:
(1.2 \(\times\) 1000) + 1000 = 6.67 \(\times\) 1.2x
1200 + 1000 = 8x
2200 = 8x
x = 275
For similar question on speed.
https://brainly.com/question/27888149
#SPJ11
50 points!!!
7. Write and solve an inequality for the value of x.

Answers
The value of x must be between -18 and -6. The solution has been obtained using Triangle inequality theorem.
What is Triangle inequality theorem?
The triangle inequality theorem explains how a triangle's three sides interact with one another. This theorem states that the sum of the lengths of any triangle's two sides is always greater than the length of the triangle's third side. In other words, the shortest distance between any two different points is always a straight line, according to this theorem.
We are given three sides of a triangle as 8, 6 and x+20
Using Triangle inequality theorem,
⇒8+6 > x+20
⇒14 > x+20
⇒-6 > x
Also,
⇒x+20+6 > 8
⇒x+26 > 8
⇒x > -18
Also,
⇒x+20+8 > 6
⇒x+28 > 6
⇒x > -22
From the above explanation it can be concluded that x is less than -6 but greater than -22 and -18.
This means that x must lie between -18 and -6.
Hence, the value of x must be between -18 and -6.
Learn more about Triangle inequality theorem from the given link
https://brainly.com/question/1163433
#SPJ1
Consider the following data drawn independently from normally distributed populations: (You may find it useful to appropriate table: z table or t table)
xˉ1 = −17.1
s1^2 = 8.4
n1=22
xˉ2 = −16.0
s2^2 = 8.7
n2 = 24
a. Construct the 90% confidence interval for the difference between the population means. Assume the population va unknown but equal. (Round final answers to 2 decimal places.)
confidence interval is __ to __
Answers
The 90% confidence interval for the difference in the population means is -2.51 to 0.31
Calculating the 90% confidence interval for the population mean differenceFrom the question, we have the following parameters that can be used in our computation:
xˉ₁ = −17.1
s₁² = 8.4
n₁ = 22
xˉ₂ = −16.0
s₂² = 8.7
n₂ = 24
Calculate the pooled variance using
P = (df₁ * s₁² + df₂ * s₂²)/df
Where
df₁ = 22 - 1 = 21
df₂ = 24 - 1 = 23
df = 22 + 24 - 2 = 44
So, we have
P = (21 * 8.4 + 23 * 8.7)/44
P = 8.56
Also, we have the standard error to be
SE = √(P/n₁ + P/n₂)
So, we have
SE = √(8.56/22 + 8.56/24)
SE = 0.86
The z score at 90% CI is 1.645, and the CI is calculated as
CI = (x₁ - x₂) ± z * SE
So, we have
CI = (-17.1 + 16.0) ± 1.645 * 0.86
This gives
CI = -1.1 ± 1.41
Expand and evaluate
CI = (-2.51, 0.31)
Hence, the confidence interval is -2.51 to 0.31
Read more about confidence interval at
https://brainly.com/question/15712887
#SPJ1
I need help!!!!! 4. Determine 3 possible solutions to the inequality below

Answers
Answer:
5,6,7
Step-by-step explanation:
the unfilled circle means that you dony inclued 4, and since the blue line is going u the scale means it can be any number higher than 4
in a systematic sampling study, if the sampling frame has 2,000 names and the desired sample size is 50, then the skip interval should be
Answers
The skip interval should be 40 if the sampling frame has 2000 names and the desired sample size is 50.
Systematic sampling is a type of sampling which uses the probability method where researchers select members of the group or population at a regular interval.
To determine the skip interval, it is necessary to first determine the sample size. Then the skip interval can be determined by dividing the total population by the target/desired sample size. Therefore;
skip interval = population / target sample size
Substituting the given values;
skip interval = 2000 / 50
skip interval = 40
Hence, the skip interval is calculated to be 40 if the frame has 2000 names and the desired sample size is 50.
To learn more about systematic sampling; click here:
https://brainly.com/question/14333907
#SPJ4
Find the 6th term of the arithmetic sequence 3x+7, x+1, −x−5,...
Answers
As a result of answering the given question, we may state that As a result, the arithmetic sequence's sixth term is -7x - 23.
What is Sequences?A sequence is an ordered list of elements in mathematics. Numbers, functions, and other mathematical objects can be used as elements. A series is frequently denoted by stating its terms in parenthesis, separated by commas. The series of natural numbers, for example, can be denoted as: (1, 2, 3, 4, 5, ...) Similarly, the series of even numbers is denoted as follows: (2, 4, 6, 8, 10, ...) Depending on whether it has a finite or infinite number of terms, a sequence might be finite or infinite.
We need to know the common difference between consecutive words to obtain the sixth term of the arithmetic sequence. By subtracting the second term from the first, we can determine the common difference:
difference in common = (x+1) - (3x+7) = -2x - 6
We can then calculate the sixth term by multiplying the common difference by 5 (3x+7):
-7x - 23 = (3x+7) + 5(-2x - 6)
As a result, the arithmetic sequence's sixth term is -7x - 23.
To know more about Sequences visit:
https://brainly.com/question/21961097
#SPJ1
Which type of mathematical problem is too complex for a classical computer to solve efficiently?
Answers
Calculating the circumference of a circle based on the circle's diameter.
What kind of problems can a quantum computer solve?
Yet another difficult area that quantum computers cater to is that of solving difficult combinatorics problems. The algorithms within quantum computing aim at solving difficult combinatorics problems in graph theory, number theory, and statistics.10 Difficult Problems Quantum Computers can Solve Easily-
Quantum encryption. Simulation of quantum systems. ab initio calculations.Solving difficult combinatorics problems.Supply chain logistics. Optimization.Finance. Drug development.Learn more about quantum computer
brainly.com/question/15188300
#SPJ4
The complete question is -
Which type of mathematical problem is too complex for a classical computer to solve efficiently?
a. converting an irregular fraction to an approximate decimal value
b. multiplying two numbers that both have a large number of digits
c. finding two prime factors that result in a specific value when multiplied
d. calculating the circumference of a circle based on the circle's diameter
what type of association would you expect to see between the length of a movie and the number of actors in the movie
Answers
Answer:
positive association
Step-by-step explanation:
The longer a movie is, the more screen time it will have, and the more actors it will probably need.
It takes 6 hours to reach London from Minneapolis. Amanda took a flight to London from Minneapolis and reached at 7:15 pm London time. At what time did she depart Minneapolis at London time?
i will mark as brainliest
please explain I will mark as brainliest
Answers
Answer:
1:15 pm
Step-by-step explanation:
It takes 6 hours to reach London from Minneapolis and she reached Minneapolis at 7:15pm so
7:15 - 6 = 1:15
As given that it takes 6 hours to reach LONDON from MINNEAPOLIS.
And Amanda reached London at 7:15
So she must have taken a flight at 7:15.-6=1:15 pm
HOPE IT HELPS!!!!
PLEASE MARK BRAINLIEST !!!!!
A research center conducted a national survey about teenage behavior. Teens were asked whether they had consumed a soft drink in the past week. The following table shows the counts for three independent random samples from three major cities.
Answers
The given table represents the counts from three independent random samples taken from three major cities regarding whether teenagers consumed a soft drink in the past week.
By summing up the counts of teenagers who consumed a soft drink from all three cities and dividing it by the total number of teenagers surveyed, we can calculate the overall proportion. Dividing this proportion by the total number of teenagers and multiplying by 100 will give us the percentage of teenagers who consumed a soft drink.
For example, if the first city had a count of 150 teenagers who consumed a soft drink out of a total of 300 surveyed, the second city had 200 out of 400, and the third city had 180 out of 350, the overall proportion would be (150 + 200 + 180) / (300 + 400 + 350) = 530 / 1050. Multiplying this by 100, we find that approximately 50.48% of teenagers consumed a soft drink in the past week based on the combined sample.
Learn more about Dividing here:
https://brainly.com/question/15381501
#SPJ11
A research center conducted a national survey about teenage behavior. Teens were asked whether they had consumed a soft drink in the past week. The following table shows the counts for three independent random samples from major cities. Baltimore Yes 727 Detroit 1,232 431 1,663 San Diego 1,482 798 2,280 Total 3,441 1,406 4,847 No 177 904 Total (a) Suppose one teen is randomly selected from each city's sample. A researcher claims that the likelihood of selecting a teen from Baltimore who consumed a soft drink in the past week is less than the likelihood of selecting a teen from either one of the other cities who consumed a soft drink in the past week because Baltimore has the least number of teens who consumed a soft drink. Is the researcher's claim correct? Explain your answer. (b) Consider the values in the table. (i) Baltimore Detroit San Diego 0 0.1 0.9 1.0 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Relative Frequency of Response (ii) Which city had the smallest proportion of teens who consumed a soft drink in the previous week? Determine the value of the proportion. (c) Consider the inference procedure that is appropriate for investigating whether there is a difference among the three cities in the proportion of all teens who consumed a soft drink in the past week. (i) Identify the appropriate inference procedure. (ii) Identify the hypotheses of the test.
In each case below list the lettered measurements for angles or sides in desending order (from greatest to least)

Answers
The lettered measurements for angles or sides in descending order is a, b, c.
What is descending order?When a pattern of numbers in mathematics has a decreasing value, the numbers are said to be in descending order. It indicates that the numbers are sorted from highest to lowest.
A format where items are arranged from highest to lowest is known as descending order. These ideas have to do with money, fractions, decimals, and numbers.
In right triangle, the sides facing the acute angles are opposite to the angles. From the given triangle, you can see that:
Side "b" is facing angle 50°
Side "c" is the smallest side which facing the unknown angle (40°)
the third side is largest side of right triangle facing the angle 90°. this is the smallest side of second triangle because of side opposite to smallest angle.
Side "a" is facing the unknown angle of second triangle (100°)
So the correct descending order is a, b, c.
To learn more about descending order visit:
brainly.com/question/23938305
#SPJ1
Suppose we have an initial value problem y′=f(x,y) with y(0.46)=y0. Further suppose that we use Euler's method with a step size h=0.0025000 to find an approximation of the solution to that initial value problem when x=0.505. In other words we approximate the value of y(0.505). If we happen to know that the 2nd derivitave of the solution satisfies ∣y′′(x)∣≤1.2847 whenever 0.46≤x≤0.505, then what is the worst case we can expect for theoretical error of the approximation? ∣e18∣≤ Find the smallest value possible, given the information you have. Your answer must be accurate to 6 decimal digits (i.e., |your answer - correct answer ∣≤0.0000005 ). Note: this is different to rounding to 6 decimal places You should maintain at least eight decimal digits of precision throughout all calculations.
Answers
The condition that ∣y′′(x)∣≤1.2847 for 0.46≤x≤0.505, the smallest possible value for ∣e18∣, which represents the error at x=0.505. The worst-case theoretical error can be approximated as 0.0025000 * 1.2847 = 0.00321175.
Euler's method is a numerical approximation technique that uses small step sizes to estimate the solution of an initial value problem. The theoretical error in the approximation can be determined by analyzing the local truncation error, which is the error introduced in a single step of the method.
In Euler's method, the local truncation error is proportional to the step size h and the second derivative of the solution. Since we know that ∣y′′(x)∣≤1.2847 for 0.46≤x≤0.505, we can use this information to estimate the worst-case theoretical error.
To find the smallest possible value for ∣e18∣, we need to determine the maximum value of the second derivative in the given interval. Since the maximum value of ∣y′′(x)∣ is 1.2847, the worst-case theoretical error at x=0.505 would be proportional to the step size h=0.0025000 and the maximum second derivative. Therefore, the worst-case theoretical error can be approximated as 0.0025000 * 1.2847 = 0.00321175.
Thus, the smallest value for ∣e18∣, accurate to six decimal places, is 0.003212.
Learn more about derivative here:
https://brainly.com/question/29144258
#SPJ11
What is the next fraction in this sequence? Simplify your answer 1/5, 1/3, 7/15, 3/5
Answers
5.
a) A builder planned to build houses. Each
house will be built on
of an acre. How
much land would be needed for houses?
Show your work.
Divide
b) The builder began with 10 acres of land.
After houses were built, how much land
was left unused?
(No links No files help asap)
Answers
Answer:
For 7 houses you will need 5.83 acres of land and the builder will have 4.16 acres of land unused
Step-by-step explanation:
The James family purchased their home in 2000 for $175,000. In 2017, they sold their home for $250,000. What is the percent change in the value of their home.
Answers
Answer:
1.4285714285714%
Step-by-step explanation:
Dividí el numero + entre -
Answer:
the answer is 42.9
Step-by-step explanation:
I need answer for number 8 please no links and the right answer thank youuu

Answers
Answer:
y = 2/5x - 4
Step-by-step explanation:
y = mx+b where m is the slope and b is the y intercept
y = 2/5x - 4
what are the features of the function f(x) = 2^x -1 graphed below
Answers
I believe it's right two down one
If A, B, and C are n x n invertible matrices, does the equation C^{-1}(A+X) B^{-1}=I_{n}C −1
(A+X)B −1
=I n
​ have a solution, X? If so, find it.
Answers
\(X = B(C^{-1})^2 - A\) is a solution to the invertible matrices equation \(C^{-1}(A+X)B^{-1}=I_n\).
We can begin by multiplying both sides of the equation by\((A+X)B^{-1}\):
\(C^{-1}(A+X)B^{-1}(A+X)B^{-1} = I_n(A+X)B^{-1}\)
Simplifying the left-hand side, we get:
\(C^{-1}(A+X)B^{-1}(A+X)B^{-1} = C^{-1}(A+X)(A+X)^{-1}C^{-1} = C^{-1}C^{-1} = (C^{-1})^2\)
Simplifying the right-hand side, we get:
\(I_n(A+X)B^{-1} = (A+X)B^{-1}\)
When we plug these values back into the original equation, we get:
\((C^{-1})^2 = (A+X)B^{-1}\)
Multiplying both sides by B, we get:
\(B(C^{-1})^2 = A+X\)
When we return to the original equation, we get:
\(C^{-1}(B(C^{-1})^2)B^{-1} = I_n\)
Simplifying, we get:
\((C^{-1})^2 = (C^{-1})^2\)
This is a true statement, so the equation has a solution,\(X = B(C^{-1})^2 - A\).
To solve the equation C^{-1}(A+X)B^{-1}=I_n, we first multiplied both sides by \((A+X)B^{-1}\) and simplified the equation to get \((C^{-1})^2 = (A+X)B^{-1}\). We then multiplied both sides by B and substituted the result back into the original equation to get \(C^{-1}(B(C^{-1})^2)B^{-1} = I_n\). Simplifying this equation, we got \((C^{-1})^2 = (C^{-1})^2\), which is a true statement. Therefore, the equation has a solution, X = \(B(C^{-1})^2 - A\).
Learn more about equation here:
https://brainly.com/question/13763238
#SPJ4
what is 1656 divided by 16
Answers
Answer:
103.5
Step-by-step explanation:
Answer:
103.5
Step-by-step explanation:
The question is,
→ what is 1656 divided by 16?
Forming as problem,
→ 1656 ÷ 16
Let's solve the problem,
→ 1656 ÷ 16
→ 103.5
Thus, the answer is 103.5.
:P HELLLP what is (13x20)5+6 = ___ - 1/3.
Answers
Answer: 1304.7
Step-by-step explanation: just took test
^. ^
260 11
Anna starts a fixed deposit with $178000, the bank offers 9.5% per year simple interest for 8 months. she has the option of restarting the investment using the interest earned as principal or cashing out at the end of the 8 months, (A) Calculate the interest due after 8 months. (B) if she restarts the investment into a new one calculate the total value of the investment at the end of the second 8 months
Answers
Using simple interest, we have that:
A) The interest due after 8 months is $11,272.33.
B) The total value of the investment will be of $189,986.24.
The amount of interest earning using simple interest, after t years, with an yearly interest rate of i and an initial investment of P is given by:
\(E = Pit\)
In this problem:
Deposit of $178,000, hence \(P = 178000\).Interest rate of 9.5% per year, hence \(i = 0.095\).8 months, the time is in years, hence \(t = \frac{8}{12} = \frac{2}{3}\)Item a:
\(E = Pit\)
\(E = 178000(0.095)\frac{2}{3} = 11272.33\)
The interest due after 8 months is $11,272.33.
Item b:
For the second interest, we consider \(P = 11272.33\), hence:
\(E_2 = Pit\)
\(E_2 = 11272.33(0.095)\frac{2}{3} = 713.91\)
The total value will be composed by:
The initial deposit of $178,000.The first interest of $11,272.33.The second interest of $713,91.Hence, it will be:
\(T = 178000 + 11272.33 + 713.91 = 189986.24\)
The total value of the investment will be of $189,986.24.
A similar problem is given at https://brainly.com/question/13176347
7x+3y=11
3x-y=23
Solve by substitution
Answers

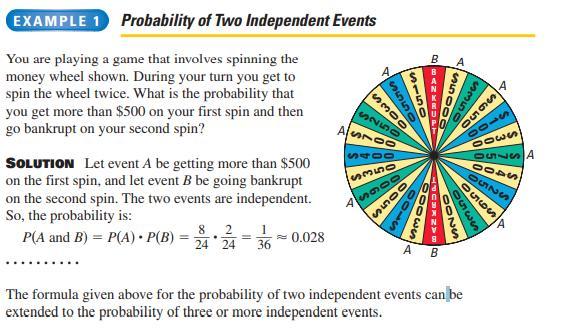
You play a game that involves spinning the money wheel shown. You spin the wheel twice. Find the probability that you get more than $500 on your first spin and then go bankrupt on your second spin. Round your answer to the nearest tenth.
Answers
Answer:
about 2.8%
Step-by-step explanation:
determine if the relationships are linear and if so are they proportional

Answers
Vertex ( 0, 2 )
Focus : ( 0, 7/4 )
Axis of symmetry : x = 0
Directrix : y = 9/4

Algebra
Find the value of x and y
(3x-y, 2) =(2, x+y)
Answers
The value of x and y in the algebra (3x - y, 2) = (2, x + y) are 1 and 1 respectively.
What is an equation?An equation is an expression that shows how numbers and variables are related to each other using mathematical operators.
Given the algebra:
(3x - y, 2) = (2, x + y)
Therefore, equation:
3x - y = 2 (1)
Also:
x + y = 2 (2)
From both equations, solving simultaneously:
x = 1, y = 1
The value of x and y are 1 and 1 respectively.
Find out more on equation at: https://brainly.com/question/29174899
#SPJ1